经典面试题
整理面试中遇到的一些常规面试题,在此记录

简单描述HTTP协议
HTTP是超文本传输协议(HyperText Transfer Protocol)的简写,它是基于TCP/IP协议的一个应用层协议。用于定义WEB客户端和WEB服务器之间交换数据的过程以及数据本身的格式。Http协议的运行分为四个过程,建立连接、发送请求信息、发送响应信息、关闭连接。HTTP协议有以下三个特点:
- 基于请求和响应。
- 无状态的,服务端不会保存客户端的状态信息。
- 连接过程是短暂的,每次连接只会处理一个请求和响应。
HTTP请求头和响应头有哪些字段
一个HTTP请求报文由请求行、请求头、空行和请求体4个部分组成
请求头:主要有3个部分的内容
对请求体的一些描述,比如请求体的内容长度和内容类型等。
客户端对服务端的一些要求,比如客户端可以接受的内容类型,可接受的语言和字符集编码等。
客户端需要在请求头中发送给服务端的数据,比如认证信息和cookie信息等。
一个HTTP响应报文由状态行、响应头、空行和响应体4个部分组成
响应头:主要是响应体的一些描述
- 比如响应体的类型,长度,语言,压缩编码类型,md5校验值等
HTTP长连接和短连接的区别
HTTP的长连接和短连接本质上是TCP长连接和短连接。
短连接:客户端和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。
长连接:当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的 TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
如何维持HTTP长连接
维持HTTP的一种最简单的方法就是就是客户端定时向服务端发送心跳,就类似于UDP聊天室里面客户端需要向服务端发送心跳来表示自己还存活一样。
常用心跳机制的实现方式
- 传统的周期检测心跳机制。其检测方法是设定一个超时时间T,只要在T之内没有接收到对方的心跳包便认为对方宕机,方法简单有效,使用比较广泛。在传统方式下,目标主机会每间隔t秒发起心跳,而接收方采用超时时间T(t<T)来判断目标是否宕机,接收方首先要非常清楚目标的心跳规律(周期为t的间隔)才能正确设定一个超时时间T,而T的选择依赖当前网络状况、目标主机的处理能力等很多不确定因素,因此在实际中往往会通过测试或估计的方式为T赋一个上限值。上限值设置过大,会导致判断“迟缓”,但会增大判断的正确性;过小,会提高判断效率,但会增加误判的可能性。由于存在网络闪断、丢包和网络拥塞等实际情况,在工程实践中,一般认为连续多次丢失心跳才可认定故障发生。
- 累计失效检测机制。随着网路负载的加大,Server心跳的接收时间可能会大于上限值T;但当网络压力减少时,心跳接收时间又会小于T,如果用一成不变的T来反映心跳状况,则会造成判断”迟缓“或误判。累计失效检测可以较好的解决这一问题,所谓的累计失效检测算法基本工作流程如下:
- 对于每一个被监控资源,检测器记录心跳信息到达时间Ti。
- 计算在统计预测范围内的到达时间的均值和方差。
- 假定到达时间的分布已知(下图包括一个正态分布的公式),我们可以计算心跳延迟(当前时间t_now和上一次到达时间Tc之间的差值) 的概率,用这个概率来判断是否发生故障,可以使用对数函数来调整它以提高可用性。在这种情况下,输出1意味着判断错误(认为节点失效)的概率是10%,2意味着1%,以此类推。
session和cookie的区别
cookie和session都是认证web客户端用户身份的会话方式。他们的区别在于:
session:如果web服务器端使用的是session,那么在认证成功之后,所有的数据都保存在服务器上,服务器只给客户端发送一个sessionid。后续客户端每次请求服务器的时候会发送当前会话的sessionid,服务器根据当前sessionid确定用户的登录状态和权限信息。
cookie:如果web服务器端使用的是cookie,那么在认证成功之后,服务器会把认证数据发送到客户端,也就是cookie。后续客户端每次请求服务器的时候都需要发送cookie,服务器根据cookie确认用户的登录状态和权限信息
全双工半双工单工
- 全双工:通信允许数据在两个方向上同时传输
- 半双工:一个时间段内只有一个动作发生。比如一条窄窄的马路,同时只能有一辆车通过,当目前有两辆车对开,这种情况下就只能一辆先过,过后另一辆再开
- 单工:只允许甲方向乙方传送信息,而乙方不能向甲方传送
TCP的三次握手和四次挥手
所谓三次握手,是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。

所谓四次挥手,是指TCP的连接的拆除需要发送四个包,因此称为四次挥手(four-way handshake)。

需要弄明白为什么需要3次握手和四次挥手,具体的解释参见:
七层模型与四层模型的区别
七层: OSI 开放系统互联参考模型,它是理论的,参考模型
物理层->数据链路层->网络层->传输层->会话层->表示层->应用层
四层: TCP/IP模型 ,现在实际应用的这一层
网际接口层->互联网层->传输层->应用层
进程线程协程的区别
进程:进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间。由于进程比较重量,占据独立的内存,进程间的切换开销比较大,但相对比较稳定安全。
线程:线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位,它与同属一个进程的其他的线程共享进程所拥有的全部资源。
协程:协程是一种用户态的轻量级线程,协程之间的切换非常快,适用于IO密集型的应用。
进程间通信的方式
- 管道(pipe)
- 信号与槽(signal)
- 消息队列(message queue)
- 共享内存(shared memory)
- 信号量(semaphore):一种锁机制
- 套接字(socket)
线程间通信的方式
- 共享进程的全局的变量
- 线程锁
数据库锁的原理以及死锁的条件
数据库锁的原理:当并发事务同时访问一个资源时,有可能导致数据不一致,数据库锁这种机制可以将数据访问顺序化,以保证数据库数据的一致性。
死锁的条件:两个或两个以上的进程(在数据库中就是两个请求)在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态,也就是系统产生了死锁。
Sql优化基本手段
- 选取最适用的字段属性
- 使用连接(JOIN)来代替子查询(Sub-Queries)
- 使用联合(UNION)来代替手动创建的临时表
- 使用索引,最常用的操作就是想尽办法让sql语句走索引
怎么看Mysql执行计划
主要是看执行计划中是否走索引,重点关注的字段:
- select_type字段的查找类型
- type字段的访问类型,常见类型有all,index,range,ref,eq_ref,const,system,NULL 性能从做至右由差至好。
- rows字段的估算行数,表示根据mysql表统计信息及索引选用情况,估算找到所需记录要读取的行数。
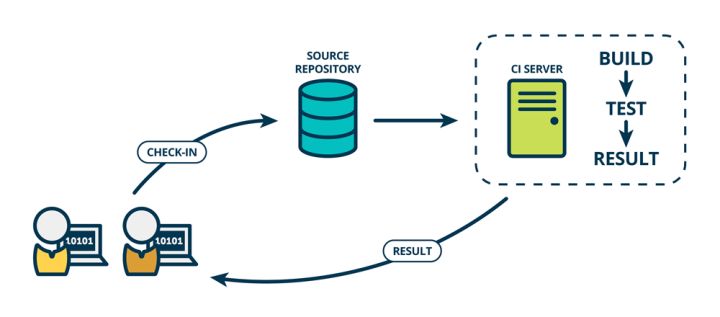
什么是CI?什么是CD?
- CI:持续集成
CONTINUOUS INTEGRATION: 持续集成强调开发人员提交了新代码之后,立刻进行构建、(单元)测试。根据测试结果,我们可以确定新代码和原有代码能否正确地集成在一起。
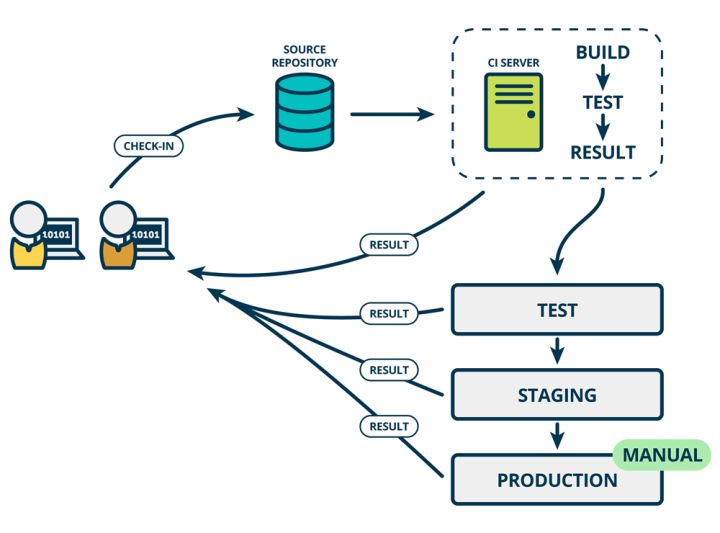
- CD:持续交付
CONTINUOUS DELIVERY:持续交付在持续集成的基础上,将集成后的代码部署到更贴近真实运行环境的「类生产环境」(production-like environments)中。比如,我们完成单元测试后,可以把代码部署到连接数据库的 Staging 环境中更多的测试。如果代码没有问题,可以继续手动部署到生产环境中。
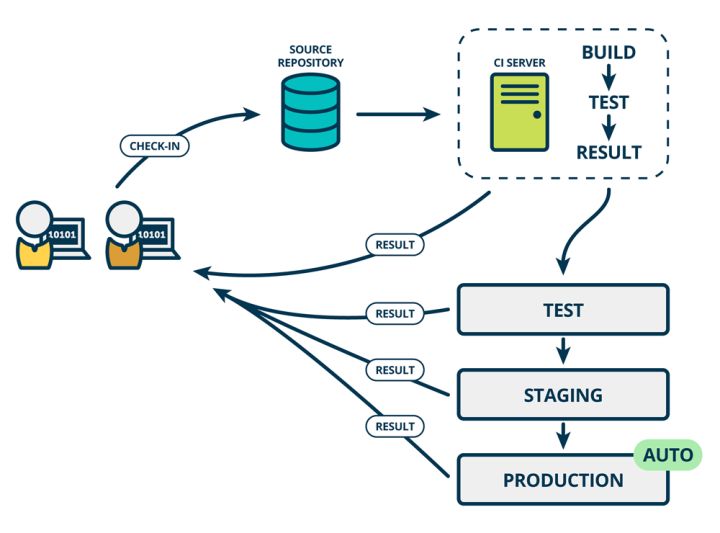
- CD:持续部署
CONTINUOUS DEPLOYMENT:持续部署则是在持续交付的基础上,把部署到生产环境的过程自动化。
使用容器部署一个Python项目
目前的部署方式都是采用完整的Python项目+supervisor进行管理,如果采用Docker部署Python项目,需要先在项目目录下创建Dockerfile文件,然后使用docker build命令构建docker镜像。将镜像分发到目标机器上使用docker run命令运行Python项目。当容器太多时可以使用容器云进行管理。
什么是死锁?用Python代码解释下
import threading
num = 0
lock = threading.Lock()
def func(n):
lock.acquire()
print n
if(n == 5):
print "到我这就锁死了"
raise Exception('大死锁之术!') # 异常抛出之后锁未释放
lock.release()
if __name__ == "__main__":
t1 = threading.Thread(target=func, args=(5,))
t2 = threading.Thread(target=func, args=(8,))
t1.start()
t2.start() 加锁需谨慎,在出现exception情况下没有try catch,所有线程都锁死了。
什么是竞争条件(Race Condition)?用Python代码解释下
# incrmnt.py
import db
def incremnt():
count = db.get_count()
new_count = count + 1
db.set_count(new_count)
return new_count在并发情况下,读取,加一,写入的操作并非原子性,会产生竞争导致最后写入数据库的结果不一样。
# 线程1和线程2同一时间在两个不同的进程中执行
# 为了方便展示把他们并排放在一起
# 垂直方向用来展示在某个时间点是那条语句在运行
# 线程 1 # 线程 2
def increment():
def increment():
# get_count return 0
count = db.get_count()
# get_count return 0 again
count = db.get_count()
new_count = count + 1
# set_count called with 1
db.set_count(new_count)
new_count = count + 1
# set_count called with 1 again
db.set_count(new_count)解决竞态条件在在数据存储层通过互斥锁使用原子操作来进行数据更新。
冒泡排序
def bubble_sort(arr):
for i in range(1, len(arr)):
for j in range(0, len(arr)-i):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
print(arr)
bubble_sort([5,9,34,3,24,12,23,2])快速排序
快速排序使用分治法(Divide and conquer)策略来把一个序列(list)分为两个子序列(sub-lists)。
步骤为:
- 从数列中挑出一个元素,称为”基准”(pivot),
- 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任何一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归到最底部时,数列的大小是零或一,也就是已经排序好了。这个算法一定会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。伪代码如下:
function quicksort(q)
var list less, pivotList, greater
if length(q) ≤ 1 {
return q
} else {
select a pivot value pivot from q
for each x in q except the pivot element
if x < pivot then add x to less
if x ≥ pivot then add x to greater
add pivot to pivotList
return concatenate(quicksort(less), pivotList, quicksort(greater))
}代码如下:
# 简单版本(翻译伪代码)
def quicksort(lst):
if len(lst) <= 1:
return lst
less = []
pivot_list = []
greater = []
pivot = lst[0]
for i in lst:
if i < pivot:
less.append(i)
elif i > pivot:
greater.append(i)
else:
pivot_list.append(i)
return quicksort(less) + pivot_list + quicksort(greater)
# 列表递推式版本
def quicksort(lst):
if len(lst) <= 1:
return lst
pivot = lst[0]
return quicksort([x for x in lst[1:] if x < pivot]) + [pivot] + quicksort([x for x in lst[1:] if x >= pivot])
# 原地分区版本(in-place partition), left和right均为index,从0开始
def quicksort(lst, left, right):
if left < right:
pivot_new_index = partition(lst, left, right)
quicksort(lst, left, pivot_new_index-1)
quicksort(lst, pivot_new_index+1, right)
def partition(lst, left, right):
pivot = lst[right]
store_index = left
for i in range(left, right):
if lst[i] <= pivot:
lst[store_index], lst[i] = lst[i], lst[store_index]
store_index += 1
lst[right], lst[store_index] = lst[store_index], lst[right]
return store_index二分查找
二分查找是一种在有序数组中查找某一特定元素的搜索算法。
经典的二分查找
搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
def binary_search(lst, low, high, key):
if low > high:
return -1
mid = (low + high) / 2
if key < lst[mid]:
return binary_search(lst, low, mid-1, key)
if key > lst[mid]:
return binary_search(lst, mid+1, high, key)
return mid有重复元素的二分查找
在一个非递减序列中,查找指定元素key所在序列中的起始下标和终止下标
思路:先通过二分查找,找到key出现的最左边的位置,如果不存在,返回-1;再通过二分查找,找到key出现的最右边的位置,如果不存在,返回-1;
def binary_search_left(lst, low, high, key):
if low > high:
return -1
mid = (low + high) / 2
if key < lst[mid]:
return binary_search_left(lst, low, mid-1, key)
if key > lst[mid]:
return binary_search_left(lst, mid+1, high, key)
if mid-1 >= low and lst[mid-1] == lst[mid]:
return binary_search_left(lst, low, mid-1, key)
return mid
def binary_search_right(lst, low, high, key):
if low > high:
return -1
mid = (low + high) / 2
if key < lst[mid]:
return binary_search_right(lst, low, mid-1, key)
if key > lst[mid]:
return binary_search_right(lst, mid+1, high, key)
if mid+1 <= high and lst[mid+1] == lst[mid]:
return binary_search_right(lst, mid+1, high, key)
return mid
def binary_search(lst, low, high, key):
left = binary_search_left(lst, low, high, key)
right = binary_search_right(lst, low, high, key)
return left, right图的BFS算法:队列
- 把根节点(起始节点)放到队列的末尾。
- 每次从队列的头部取出一个元素,查看这个元素所有的下一级元素,把它们放到队列的末尾。并把这个元素记为它下一级元素的前驱。
- 找到所要找的元素时结束程序。
- 如果遍历整个树还没有找到,结束程序。
图的DFS算法:栈
- 访问顶点v;
- 依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
- 若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历
A*算法
https://zh.wikipedia.org/wiki/A*%E6%90%9C%E5%AF%BB%E7%AE%97%E6%B3%95https://www.cnblogs.com/yanlingyin/archive/2012/01/15/2322640.html欧几里得距离:欧几里得空间中两点间的直线距离
曼哈顿距离: 两点在南北方向上的距离加上在东西方向上的距离
切比雪夫距离:二点之间的距离定义为其各坐标数值差的最大值
max(|x2-x1|,|y2-y1|)
Dijkstra算法
Dijkstra(迪杰斯特拉)算法是典型的单源最短路径算法,用于计算一个节点到其他所有节点的最短路径。
算法思想:设G=(V,E)是一个带权有向图,把图中顶点集合V分成两组,第一组为已求出最短路径的顶点集(用S表示,初始时S中只有一个源点,以后每求得一条最短路径 , 就将加入到集合S中,直到全部顶点都加入到S中,算法就结束了),第二组为其余未确定最短路径的顶点集合(用U表示),按最短路径长度的递增次序依次把第二组的顶点加入S中。在加入的过程中,总保持从源点v到S中各顶点的最短路径长度不大于从源点v到U中任何顶点的最短路径长度。此外,每个顶点对应一个距离,S中的顶点的距离就是从v到此顶点的最短路径长度,U中的顶点的距离,是从v到此顶点只包括S中的顶点为中间顶点的当前最短路径长度。
算法步骤:
- 初始时,
S只包含源点,即S={v},v的距离为0。U包含除v外的其他顶点,即:U={其余顶点},若v与U中顶点u有边,则<u,v>正常有权值,若u不是v的出边邻接点,则<u,v>权值为∞。 - 从
U中选取一个距离v最小的顶点k,把k加入S中(该选定的距离就是v到k的最短路径长度)。 - 以
k为新考虑的中间点,修改U中各顶点的距离;若从源点v到顶点u的距离(经过顶点k)比原来距离(不经过顶点k)短,则修改顶点u的距离值,修改后的距离值的顶点k的距离加上边上的权。 - 重复步骤2和3直到所有顶点都包含在S中。
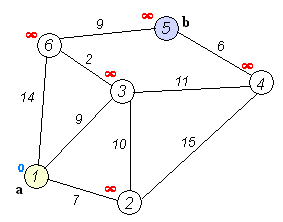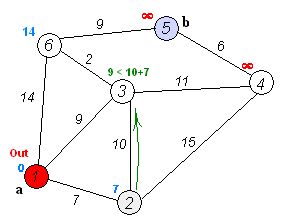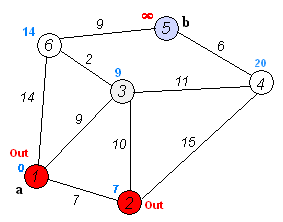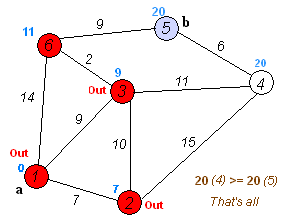
Floyd算法
Floyd算法是解决任意两点间的最短路径的一种算法,Floyd算法是一个经典的动态规划算法。算法任意两点之间的距离矩阵。
let dist be a |V| × |V| array of minimum distances initialized to ∞ (infinity)
for each vertex v
dist[v][v] ← 0
for each edge (u,v)
dist[u][v] ← w(u,v) // the weight of the edge (u,v)
for k from 1 to |V|
for i from 1 to |V|
for j from 1 to |V|
if dist[i][j] > dist[i][k] + dist[k][j]
dist[i][j] ← dist[i][k] + dist[k][j]
end if啤酒瓶问题
1块钱一瓶水2个空瓶子换1瓶有20瓶可以喝到几瓶,并且可以临时赊欠
def calc(money):
"""每个空瓶都借一瓶水,能喝的水就是钱数乘2"""
return money * 2
print calc(20)1块钱一瓶水2个空瓶子换1瓶有20瓶可以喝到几瓶,不可以临时赊欠
def calc(money):
# 初始可以喝money瓶水,有money个瓶子
return _calc(money, money)
def _calc(drink_bottle, empty_bottle_num):
if empty_bottle_num == 0 or empty_bottle_num == 1:
return drink_bottle
return _calc(drink_bottle + empty_bottle_num/2, empty_bottle_num % 2 + empty_bottle_num/2)
print calc(5)一元钱一瓶水,两个空瓶可以换一瓶,三个盖儿可以换一瓶,20元最多能喝多少? 不可以临时赊欠
def calc(money):
# 初始可以喝money瓶水,有money个瓶子, 有money个盖子
return _calc(money, money, money)
def _calc(drink_bottle, empty_bottle_num, bottle_cap_num):
while empty_bottle_num >= 2 or bottle_cap_num >= 3:
drink_bottle, empty_bottle_num, bottle_cap_num = _handle1(drink_bottle, empty_bottle_num, bottle_cap_num)
drink_bottle, empty_bottle_num, bottle_cap_num = _handle2(drink_bottle, empty_bottle_num, bottle_cap_num)
return drink_bottle
def _handle1(drink_bottle, empty_bottle_num, bottle_cap_num):
if empty_bottle_num <= 1:
return drink_bottle, empty_bottle_num, bottle_cap_num
return _handle1(drink_bottle+empty_bottle_num/2, empty_bottle_num % 2 + empty_bottle_num/2,
bottle_cap_num+empty_bottle_num/2)
def _handle2(drink_bottle, empty_bottle_num, bottle_cap_num):
if bottle_cap_num <= 2:
return drink_bottle, empty_bottle_num, bottle_cap_num
return _handle2(drink_bottle+bottle_cap_num/3, empty_bottle_num+bottle_cap_num/3,
bottle_cap_num % 3 + bottle_cap_num/3)
print calc(20)青蛙跳台阶问题
一只青蛙可以一次跳一级台阶,也可以一次跳两级台阶,如果青蛙要跳上n级台阶,共有多少钟跳法?
当青蛙即将跳上n级台阶时,共有两种可能性,一种是从n-1级台阶跳一步到n级,另外一种是从n-2级台阶跳两步到n级,所以求到n级台阶的所有可能性f(n)就转变为了求到n-2级台阶的所有可能性f(n-2)和到n-1级台阶的所有可能性f(n-1)之和,以此类推至最后f(2)=f(0)+f(1)=1+1。递推公式就是f(n) = f(n - 1) + f(n - 2)
/ 1 n=1
f(n)= 2 n=2
\ f(n-1)+(f-2) n>2如果青蛙一次可以跳1到n之间的任意阶,那么此时需要采用裂项相消的方法计算。参考:
斐波拉契数列问题
递归: 时间复杂度O(2^n)
def fib(n):
if n == 0 or n == 1:
return 1
else:
return fib(n-1) + fib(n-2)递推: 时间复杂度O(n)
def fib(n):
if n == 0 or n == 1:
return 1
a = b = 1
for i in range(2, n+1):
c = a + b
a, b = b, c
return b矩阵求解的方法忽略。
参考:https://www.cnblogs.com/xudong-bupt/archive/2013/03/19/2966954.html
微博短链接设计
TinyUrl问题:
http://wdxtub.com/interview/14520604447653.html
https://www.zhihu.com/question/29270034
为什么一个语言中,”函数是第一公民”是很重要的
函数作为第一功名时,函数本身可以作为传递的对象,而在c语言中函数只是一段程序代码,它不是一个对象,函数名则是函数的地址,因此我们只能通过指针——通过传递地址的方式来解决。
理解Restful api架构
Rest全称是 Resource Representational State Transfer(前面的主语Resource被省略掉了),通俗来讲就是:资源在网络中以某种表现形式进行状态转移。分解开来:
Resource:资源,即数据(前面说过网络的核心)。比如 newsfeed,friends等;
Representational:某种表现形式,比如用JSON,XML,JPEG等;
State Transfer:状态变化。通过HTTP动词实现。
之前的PHP,JSP等。在之前的桌面时代问题不大,但是近年来移动互联网的发展,各种类型的Client层出不穷,RESTful可以通过一套统一的接口为 Web,iOS和Android提供服务。
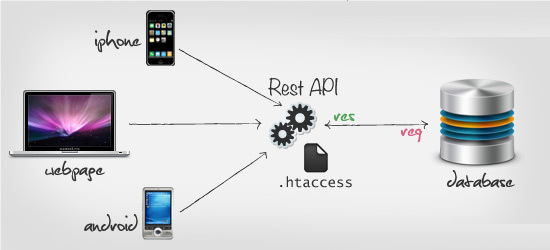
Restful api架构设计规范
- http://www.ruanyifeng.com/blog/2014/05/restful_api.html
- http://blog.gusibi.com/post/build_restful_api_by_swagger/
nginx的使用
一个完整的nginx配置一般情况下会包含5个通用的配置
- 共用的配置,比如指定pid,限制连接数,是否使用epoll之类的
- Upstream模块:通过upstream模块实现负载均衡
- http模块:入口模块
- http中的server模块:http中可以有多个server,一个server就是一个站点
- http中的location模块:匹配url
nginx最常用的操作是:实现restful api的负载均衡,可以分发到多个server节点。
权限系统的设计
- 用户表-角色表-权限表-资源表
- 用户角色关联表
- 角色资源权限关联表

Redis
两种持久化
- 快照RDB:会在一个特定的间隔保存那个时间点的一个数据快照。
- 追加AOF:会记录每一个服务器收到的写操作
缓存穿透
请求去查询一条压根儿数据库中根本就不存在的数据,也就是缓存和数据库都查询不到这条数据,但是请求每次都会打到数据库上面去。
这种查询不存在数据的现象我们称为缓存穿透。
解决方法:
- 缓存空值:空数据的key有限,重复率比较高的,采用这种方式进行缓存
- 在缓存之前在加一层 BloomFilter ,在查询的时候先去 BloomFilter 去查询 key 是否存在,如果不存在就直接返回,存在再走查缓存 -> 查 DB。空数据的Key较多时,采用这种方法
缓存击穿
在平常高并发的系统中,大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿。
解决办法:在第一个请求穿过缓存查询数据库的时候加互斥锁,取到数据之后加缓存
缓存雪崩
当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了,会有大量的请求进来直接打到DB上面。结果就是DB 称不住,挂掉。
解决办法:
- 事前
- 使用集群缓存,保证缓存服务的高可用
- 设置不同的失效时间:在一个基础的时间上加上或者减去一个范围内的随机值
- 事中:使用本地缓存 + Hystrix限流&降级,避免MySQL被打死
- 事后:开启redis持久化机制,从rdb或者aof尽快恢复缓存集群
Celery
使用RabbitMQ做broker,用 Django ORM 配合数据库 做 Result Backend。
为什么不使用redis做broker:
- 如果使用Redis,强行重启 Worker的时候不丢消息但任务可能会不执行, RabbitMQ 则一切正常
- 另外redis要注意开启持久化
Celery内存泄漏问题:
celery配置项如下
CELERYD_CONCURRENCY = 2 celery worker并发数
CELERYD_MAX_TASKS_PER_CHILD = 5 每个worker最大执行任务数执行celery -A ansibleAPI.celery worker启动celery,通过ps -ef | grep celery可以看到两个celery worker进程(8226,8228)。
利用celery worker进行某个任务,当worker没有执行到最大任务时(即销毁重建),每执行一次任务占用内存必然有所增加,任务数为9,10时(celery均匀调度,并发数*最大任务数),分别有原8228 worker被销毁,重新创建9386 worker及原8226 worker被销毁,重新创建9564 worker,此时,运行第9次时,占用总内存有所下降,运行第10次时,总内存回到初如值,同样任务执行第19、20次情况类似。
celery并发计算规则
celery任务并发只与celery配置项CELERYD_CONCURRENCY 有关,与CELERYD_MAX_TASKS_PER_CHILD没有关系,即CELERYD_CONCURRENCY=2,只能并发2个worker,此时任务处理较大的文件时,执行两次可以看到两个task任务并行执行,而执行第三个任务时,开始排队,直到两个worker执行完毕。
结论
celery执行完任务不释放内存与原worker一直没有被销毁有关,因此CELERYD_MAX_TASKS_PER_CHILD可以适当配置小点,而任务并发数与CELERYD_CONCURRENCY配置项有关,每增加一个worker必然增加内存消耗,同时也影响到一个worker何时被销毁,因为celery是均匀调度任务至每个worker,因此也不宜配置过大,适当配置。
Kafka
RabbitMQ
Pulsar
K8s
大数据
熔断
降级一般而言指的是我们自身的系统出现了故障而降级。而熔断一般是指依赖的外部接口出现故障的情况断绝和外部接口的关系。
例如你的A服务里面的一个功能依赖B服务,这时候B服务出问题了,返回的很慢。这种情况可能会因为这么一个功能而拖慢了A服务里面的所有功能,因此我们这时候就需要熔断!即当发现A要调用这B时就直接返回错误(或者返回其他默认值啊啥的),就不去请求B了。我这还是举了两个服务的调用,有些那真的是一环扣一环,出问题不熔断,那真的是会雪崩。
当然也有人认为熔断不就是降级的一种的,我觉得你非要说熔断也属于一种降级我也没法反驳,但是它们本质上的突出点和想表达的意思还是有一些不同的。
那什么时候熔断合适呢?也就是到达哪个阈值进行熔断,5分钟内50%的请求都超过1秒?还是啥?参考降级。
限流
上面说的两个算是请求过来我们都受理了,这个限流就更狠了,直接跟请求说对不起再见!也就是系统规定了多少承受能力,只允许这么些请求能过来,其他的请求就说再见了。
一般限制的指标有:请求总量或某段时间内请求总量。
请求总量:比如秒杀的,秒杀100份产品,我就放5000名进来,超过的直接拒绝请求了。
某段时间内请求总量:比如规定了每秒请求的峰值是1W,这一秒内多的请求直接拒绝了。咱们下一秒再见。
降级
降级也就是服务降级,当我们的服务器压力剧增为了保证核心功能的可用性 ,而选择性的降低一些功能的可用性,或者直接关闭该功能。这就是典型的丢车保帅了。 就比如贴吧类型的网站,当服务器吃不消的时候,可以选择把发帖功能关闭,注册功能关闭,改密码,改头像这些都关了,为了确保登录和浏览帖子这种核心的功能。
一般而言都会建立一个独立的降级系统,可以灵活且批量的配置服务器的降级功能。当然也有用代码自动降级的,例如接口超时降级、失败重试多次降级等。具体失败几次,超时设置多久,由你们的业务等其他因素决定。开个小会,定个值,扔线上去看看情况。根据情况再调优。
秒杀
CAP理论
先看一个小例子:
一些商品要缓存到redis里,高并发度,低并发写,要怎么缓存?
- 写完mysql去更新redis就行。如果不一致就按照CAP理论用下面的方法处理
网络抖动就是P,C就是强一致性,A就是可用性,满足cp还是满足ap
cp就是写redis失败,就让写入mysql也失败,也就是不满足可用性
ap就是写redis失败,就找个地方存起来,或者mysql上标记下,后面补偿写
事务的级别
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
- 未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
- 提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)
- 可重复读(Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读
- 串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
Mysql 默认的事务隔离级别是可重复读REPEATABLE_READ,并且通过GAP锁解决幻读的问题
Oracle默认的事务隔离级别是读已提交READ_COMMITTED
不可重复读和幻读的区别
不可重复读重点在于update和delete,而幻读的重点在于insert。
如果使用锁机制来实现这两种隔离级别,在可重复读中,该sql第一次读取到数据后,就将这些数据加锁,其它事务无法修改这些数据,就可以实现可重复读了。但这种方法却无法锁住insert的数据,所以当事务A先前读取了数据,或者修改了全部数据,事务B还是可以insert数据提交,这时事务A就会发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免。需要Serializable隔离级别 ,读用读锁,写用写锁,读锁和写锁互斥,这么做可以有效的避免幻读、不可重复读、脏读等问题,但会极大的降低数据库的并发能力。
所以说不可重复读和幻读最大的区别,就在于如何通过锁机制来解决他们产生的问题。
上文说的,是使用悲观锁机制来处理这两种问题,但是MySQL、ORACLE、PostgreSQL等成熟的数据库,出于性能考虑,都是使用了以乐观锁为理论基础的MVCC(多版本并发控制)来避免这两种问题。
行锁防止别的事务修改或删除,GAP锁防止别的事务新增,行锁和GAP锁结合形成的的Next-Key锁共同解决了RR级别在写数据时的幻读问题。
Springboot事务隔离
public enum Isolation {
DEFAULT(-1), // 默认的是使用数据库当前隔离级别
READ_UNCOMMITTED(1),
READ_COMMITTED(2),
REPEATABLE_READ(4),
SERIALIZABLE(8);
}Springboot事务传播行为
public enum Propagation {
REQUIRED(0),
SUPPORTS(1),
MANDATORY(2),
REQUIRES_NEW(3),
NOT_SUPPORTED(4),
NEVER(5),
NESTED(6);
}Python的gc机制
python引用计数 + 分代收集和标记清除(处理循环引用),进行垃圾回收
标记清除(Mark Sweep)
- 标记清除算法主要分为标记阶段和清除阶段。标记阶段是把所有活动对象做上标记。清除阶段是把那些没有标记的对象,也就是非活动对象进行回收。
分代收集(Generational Collection)算法
- 对于一个大型的系统,当创建的对象和方法变量比较多时,堆内存中的对象也会比较多,如果逐一分析对象是否该回收,那么势必造成效率低下。分代收集算法是基于这样一个事实:不同的对象的生命周期(存活情况)是不一样的,而不同生命周期的对象位于堆中不同的区域,因此对堆内存不同区域采用不同的策略进行回收可以提高 JVM 的执行效率。
- 分代收集可以说是以上几种算法的混合运用,不同代不同回收算法。
https://oangeor.github.io/2017/08/06/python-vs-java-gc-1/
https://oangeor.github.io/2017/08/13/python-vs-java-gc-2/
面试介绍
我叫陈亮,有3年半工作经验,之前主要做的是web后端|运维开发|大数据这三块
参考:
- Github-后端开发常用面试题整理
- [Github-CyC2018 LeetCode刷题目录](https://github.com/CyC2018/CS-Notes/blob/master/notes/Leetcode 题解 - 目录.md)