重新认识HTTP3xx重定向机制
问题引入
前段时间做数据收集时需要下载网宿cdn的日志进行分析。而网宿对日志下载的接口搞得很复杂,又没有提供相应的sdk,只是提供了一个shell脚本,虽然在ubuntu上使用很方便,但是脚本里面的各种重定向分析非常复杂。故此想对重定向在深入了解一点。
查询网宿日志列表的脚本
#!/bin/sh
TMP_FILE="/tmp/wslog_query_client.log"
#Usage
Usage() {
echo "wslog_query_client.sh [query_url] [user] [passwd] [start_time] [end_time] [channels]"
return 0
}
#check input parameters
if [ $# -eq 1 ]; then
if [ "$1" = "-h" ]; then
Usage
exit 0
else
Usage
exit -1
fi
elif [ $# -ne 6 ]; then
Usage
exit -1
fi
#params set
url=$1
user=$2
passwd=`echo $3 | sed 's/&/%26/g' `
start_time=$4
end_time=$5
channels=$6
#access logQuery access API
curl -s -D $TMP_FILE $1
cat $TMP_FILE | grep "HTTP/" | grep "302" > /dev/null
if [ $? -ne 0 ]; then
exit -2
fi
#redirect to verify url with user and passwd
TMP_URL=`cat $TMP_FILE | grep "Location: "|sed 's/\r//' | awk '{print $2}' | sed 's/http:/https:/'`
TMP_URL="${TMP_URL}?u=$user&p=$passwd&channel=$channels"
curl -s -k -D $TMP_FILE $TMP_URL
cat $TMP_FILE | grep "HTTP/" | grep "302" > /dev/null
if [ $? -ne 0 ]; then
exit -3
fi
#redirect to query url with start_time, end_time and channels
TMP_URL=`cat $TMP_FILE | grep "Location: "|sed 's/\r//' | awk '{print $2}'`
TMP_URL="${TMP_URL}&start_time=$start_time&end_time=$end_time&channels=$channels"
curl -s -D $TMP_FILE $TMP_URL
#check query result
cat $TMP_FILE | grep "HTTP/" | grep "200" > /dev/null
if [ $? -ne 0 ]; then
if
cat $TMP_FILE | grep "HTTP/" | grep "404" > /dev/null
then
exit -404
else
exit -4
fi
fi
exit 0
脚本调用命令和结果(用户名,密码,domain,wskey均已处理,调用结果只有参考作用)
root@sz3:/tmp# sh /root/wslog_query_client.sh "http://dx.wslog.chinanetcenter.com/logQuery/access" user1 passwd1 2017-08-30-0000 2017-08-30-2359 "rtmp-wsz.enterprise.com"
{"logs": [{"domain": "rtmp-wsz.enterprise.com", "files": [{"size": 4320, "end_time": "2017-08-30-1159", "start_time": "2017-08-30-0000", "url": "http://dx.wslog.chinanetcenter.com/log/qukan/rtmp-wsz.enterprise.com/2017-08-30-0000-1130_rtmp-wsz.enterprise.com.cn.log.gz?wskey=e4030060bdfe9d5600a77726c5900d07aa3adae00e8b2"}, {"size": 8006, "end_time": "2017-08-30-2359", "start_time": "2017-08-30-1200", "url": "http://dx.wslog.chinanetcenter.com/log/qukan/rtmp-wsz.enterprise.com/2017-08-30-1200-2330_rtmp-wsz.enterprise.com.cn.log.gz?wskey=3772006094880e8300a73cc2c59006bfeea33ae00d9da"}]}]}脚本的调用过程是根据参数一步一步的进行302重定向,重定向时会依赖于参数,每次重定向依赖的参数都不相同,不仅仅是url跳转,如果直接使用以下http链接则无法跳转到,因此需要按照shell脚本那样一层一层解析。
http://dx.wslog.chinanetcenter.com/logQuery/access?user=user1&passwd=passwd1&channels=rtmp-wsz.enterprise.com&start_time=2017-08-30-0000&end_time=2017-08-30-2359HTTP重定向的原理

客户端发起http请求,如果服务端返回http重定向响应,那么客户端会请求返回的新url,这就是重定向的过程,这个过程就是重定向。在客户端和服务端之间自动完成,用户不可见。
不同类型的重定向映射可以划分为三个类别:永久重定向、临时重定向和特殊重定向。
如果你想把自己的网站永久更改为一个新的域名,则应该使用301永久重定向,搜索引擎机器人会在遇到该状态码时触发更新操作,在其索引库中修改与该资源相关的 URL 。
HTTP重定向的使用
主要以Python和shell两种语言来介绍http重定向的使用。
Python
Python常用的http库urllib,urllib2,requests都支持http重定向。以requests库为例做介绍。
import requests
def get_final_link(url):
try:
r = requests.get(url=url, allow_redirects=False)
if r.status_code == 302 or r.status_code == 301:
return get_final_link(r.headers['Location'])
else:
return r.url
except:
return url
def get_final_link1(url):
r = requests.get(url=url, allow_redirects=True)
for rsp in r.history:
print rsp.url
return r.url
print get_final_link(url='http://runreport.dnion.com/DCC/logDownLoad.do?user=user1&password=password1&domain=rtmpdist-d.quklive.com&date=20171026&hour=10')
print get_final_link(url='https://github.com')
print get_final_link(url='http://github.com')
print get_final_link1(url='http://github.com') # 会发生301重定向如果确定重定向的过程中全部都是http(s)请求,则allow_redirects参数设置成True即可得到最终的http链接。如果不是则需要自己进行递归解析。
如果是要简单的下载文件,则可以使用urllib.urlretrieve轻松胜任,即使最终链接是ftp。
Shell
使用curl命令模拟
-L参数,当页面有跳转的时候,输出跳转到的页面
-I参数 header信息 当有跳转时,可以通过 curl -L -I URL|grep Location 来确定跳转到的新url地址
root@sz3:~# curl -L -I "http://runreport.dnion.com/DCC/logDownLoad.do?user=user1&password=password1&domain=rtmpdist-d.quklive.com&date=20171026&hour=10"
HTTP/1.1 302 Moved Temporarily
Server: Apache-Coyote/1.1
Set-Cookie: JSESSIONID=0F11668F6EBF4DC16B43E322CCF16C85; Path=/DCC
Location: http://runreport.dnion.com/logDownLoad.do?user=qukan&password=0cddcbf6d292fab5de0aas931bf19c&domain=rtmpdist-d.quklive.com&date=20171026&hour=10
Content-Type: text/html;charset=GBK
Content-Length: 0
Date: Mon, 06 Nov 2017 09:46:44 GMT
HTTP/1.1 302 Moved Temporarily
Server: Apache-Coyote/1.1
Location: ftp://ABA606843D412DAE34F28CDB23F7A31E:0687B16F2F5D0A2637FACDB23FAC982179411FA7466F10B2E7D0F4AA2D7F6AD42536F122549D0A6E40337E896@125.39.237.48:55621/rtmpdist-d.quklive.com_20171026_10_11.gz
Content-Type: text/html;charset=GBK
Content-Length: 0
Date: Mon, 06 Nov 2017 09:46:44 GMT
Last-Modified: Thu, 26 Oct 2017 02:30:13 GMT
Content-Length: 1932
Accept-ranges: bytes最后跳转到需要的ftp链接。
HTTP重定向抓包验证
使用wireshark抓包结果如下:
第一次跳转过程如下图
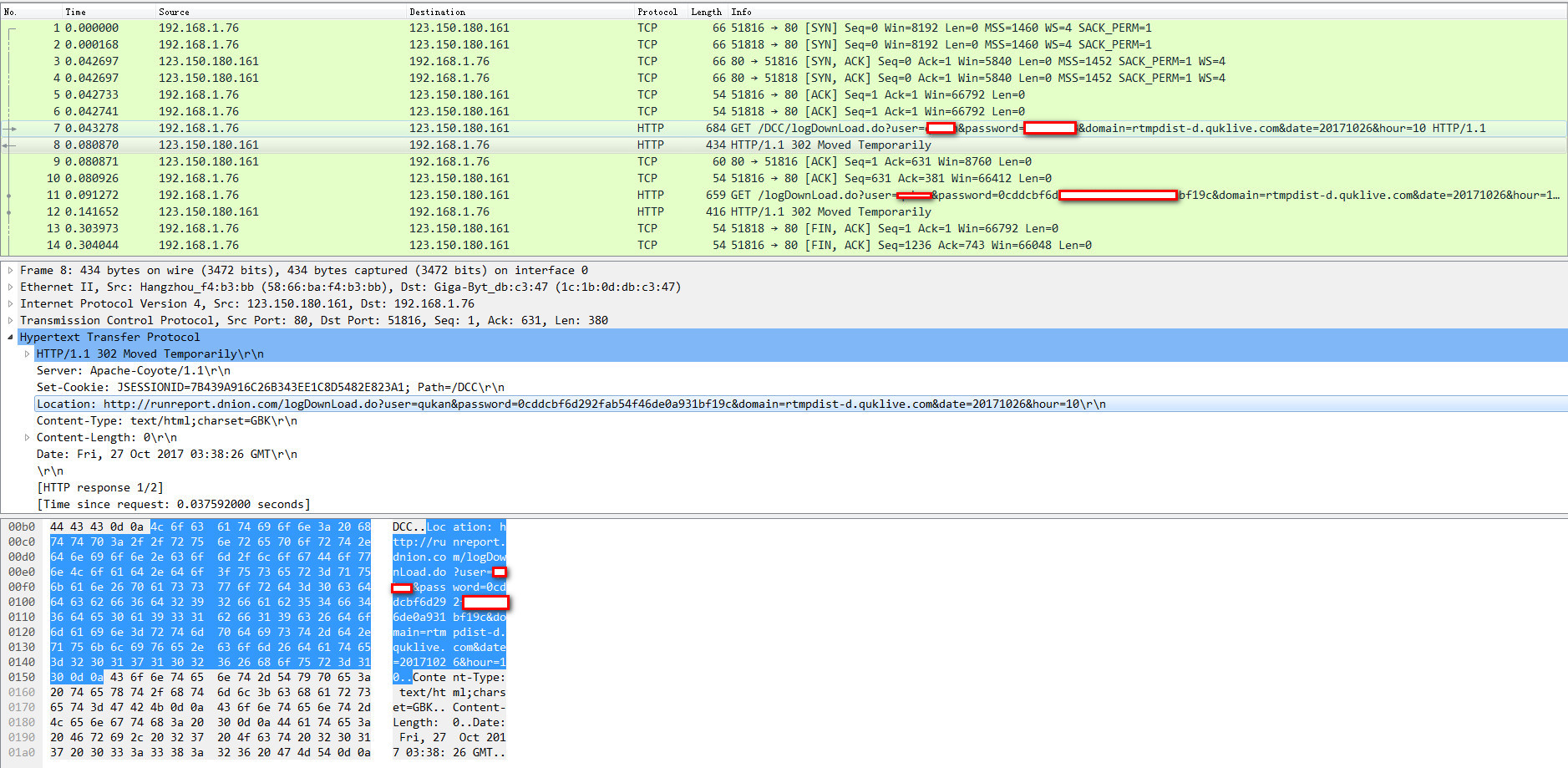
第二次跳转过程如下图
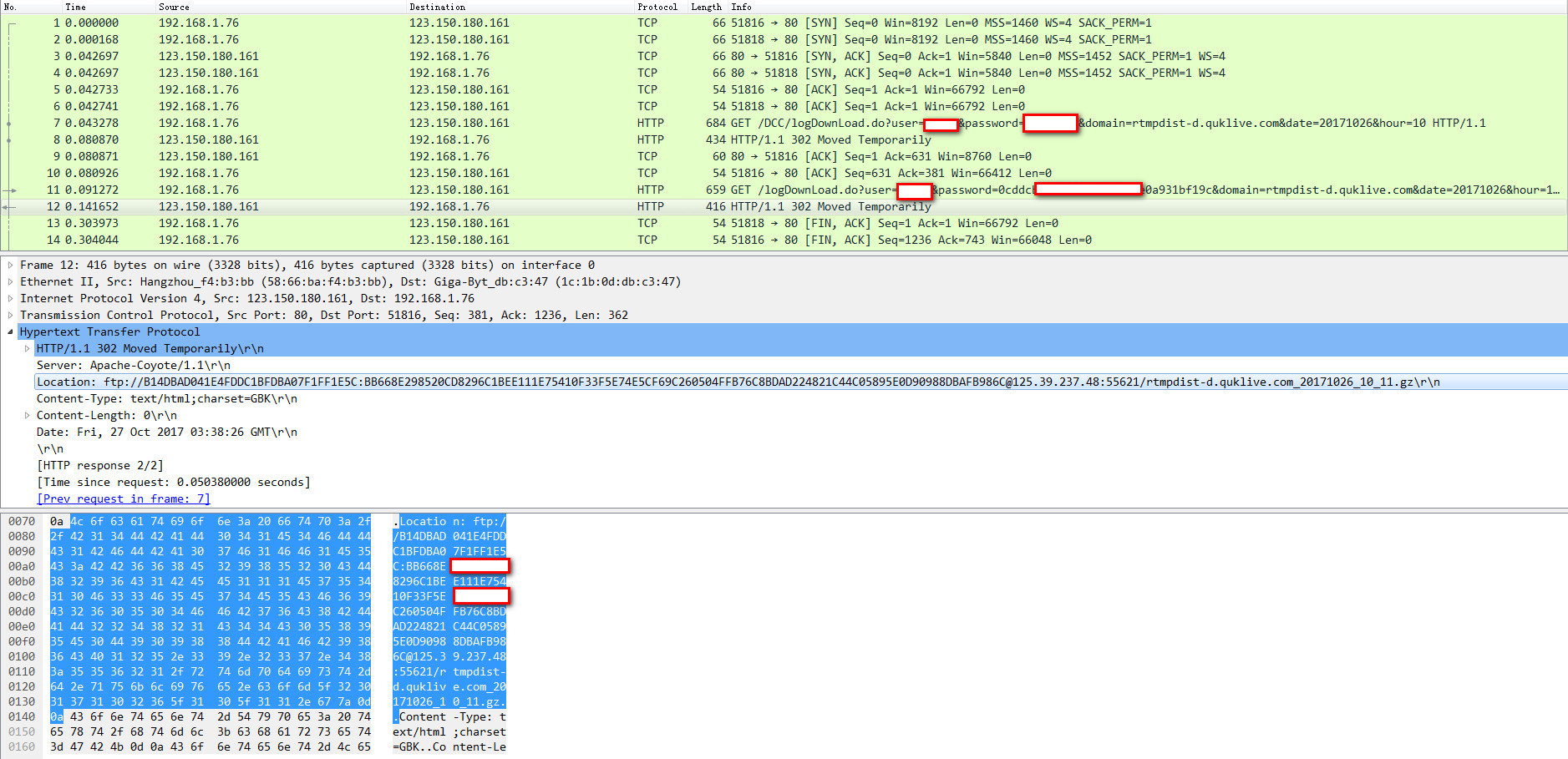
所以通过抓包可以清晰的看到302跳转的过程
参考: