Hadoop项目:从cdn日志统计直播流量
从在用的四家cdn的大量日志中,统计出每场直播的流量数据,包括国内流量和海外流量。
获取日志
目前已有的数据来源:四家cdn服务商。每个服务商都有自己不同的日志接口,不同的日志获取方式,可以把日志类型分为:
网宿日志、帝联日志、阿里日志,腾讯日志
直播日志、录播日志
hls日志、rtmp日志、rtmpdist日志、hdl日志,不同协议日志的域名都不相同。
各家厂商cdn日志的收集方法参见各自官网。获取到的日志示例文件名如下:
| cdn_code | log_name |
|---|---|
| netcenter | 2017-12-06-2300-2330_rtmp-wsz.qukanvideo.com.cn.log.gz |
| dnion | hls-d.quklive.com_20180509_03_04.gz |
| alicdn | play-a.quklive.com_2017_12_07_1100_1200.gz |
| qukan->alicdn | recordcdn-sz.qukanvideo.com_2017_12_06_1800_1900.gz |
| tencent | 2017120607_hangzhouqukan.cdn.log.gz |
可以从文件名判断属于日志所属的cdn代码和对应的协议。将cdn代码、播放类型代码、协议代码对应的关系直接存在字典中:
domain_protocol_dict = {
'recordcdn.quklive.com': ('qukan', 'record', 'hls'),
...
}通过日志名称匹配到域名,并取得对应的cdn代码、播放类型代码、协议代码,然后对具体的日志做不同的正则处理。
日志存入HDFS
直接使用hdfs命令拷贝到HDFS中
通过日志下载程序调用接口下载到的日志可以使用以下命令直接拷贝到hdfs,拷贝成功一个日志,就删除对应的本地文件系统日志。示例命令如下:
hdfs dfs -put /tmp/2018-05-09-0000-0030_rtmpdist-wsz.qukanvideo.com.cn.log.gz cdn_log使用分布式日志收集系统flume导入到HDFS中
对于用户访问日志的采集,更多的是使用flume,并且会将采集的数据保存到HDFS中 。虽然本次项目日志不需要采用此种方式,但是也可以作为一个手段。flume在分布式日志收集上比较类似于ELK中的logstash,可以对比学习下。最简单(单agent)的数据流模型如下:
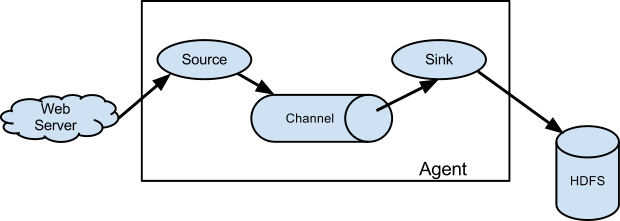
具体使用方法参见:Flume 1.8.0 User Guide
hadoop压缩日志
各个cdn厂商提供的cdn日志都是gz格式的压缩日志,因此必须考虑对压缩日志的处理。Hadoop3 对于压缩格式是自动识别的。如果我们压缩的文件有相应压缩格式的扩展名(比如 lzo,gz,bzip2 等)。Hadoop 会根据压缩格式的扩展名自动选择相对应的解码器来解压数据,此过程完全是 Hadoop 自动处理,我们只需要确保输入的压缩文件有扩展名。因此这一步可以直接省略自行解压的操作。
但是需要注意在mapper环境变量中得到的输入文件的文件名是解压之前的文件名,也就是带压缩扩展名的。在hadoop3中可以通过以下变量验证:
import os
input_file_path = os.environ['mapreduce_map_input_file']需要稍微注意的地方有两点:
- input_file_path保存的是文件在hdfs上的完整路径。 比如:
hdfs://node-master:9000/user/hadoop/cdn_log/2018-05-09-0100-0130_rtmpdist-wsz.qukanvideo.com.cn.log.gz - 老版本的api为
map_input_file,在集群上尝试了老版本的api,代码会报错。
MR程序
具体代码参见Github:https://github.com/Flowsnow/hadoop-mapreduce-demo
需要先确定mapper和redecer中间的数据格式,需要考虑到shuffle。因为最终是要按照live_id分组进行统计,因此live_id作为key,中间数据如下:
formatted_line = '\t'.join([live_id, datetime_str, ip, up_flow, down_flow])使用'\t'分隔,ip用于后续判断属于国内还是海外。
flow_statistic_mapper.py
主要从各个cdn日志中筛选出有效的格式化数据,因此最多的操作就是对日志文件名和日志每一行进行正则匹配。
flow_statistic_reducer.py
根据ip查询是国内流量还是海外流量,对每场直播进行统计。
代码调试
使用linux管道、cat命令、sort命令综合使用进行调试,示例调试命令如下:
cat /tmp/2018-05-09-0000-0030_rtmpdist-wsz.qukanvideo.com.cn.log | python flow_statistic_mapper.py | sort -t $'\t' -k1,1 | python flow_statistic_reducer.py因为原始日志是压缩格式的,因此调试时可以先把日志解压然后调试,相对应的mapper中的输入文件名称也会有变化,需要注意。
MR调用
命令和执行结果如下:
hadoop@node-master:~/workspace/flow_statistic$ hadoop jar /usr/local/src/hadoop-3.1.0/share/hadoop/tools/lib/hadoop-streaming-3.1.0.jar -file flow_statistic_mapper.py -mapper 'python flow_statistic_mapper.py' -file flow_statistic_reducer.py -reducer 'python flow_statistic_reducer.py' -input all_cdn_logs/*.gz -output output-flow
2018-05-15 19:14:26,975 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead.
packageJobJar: [flow_statistic_mapper.py, flow_statistic_reducer.py, /tmp/hadoop-unjar3114046136813781093/] [] /tmp/streamjob6407868495582297159.jar tmpDir=null
2018-05-15 19:14:28,667 INFO client.RMProxy: Connecting to ResourceManager at node-master/120.77.239.67:18040
2018-05-15 19:14:28,944 INFO client.RMProxy: Connecting to ResourceManager at node-master/120.77.239.67:18040
2018-05-15 19:14:29,587 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1526300938491_0016
2018-05-15 19:14:30,598 INFO mapred.FileInputFormat: Total input files to process : 24
2018-05-15 19:14:30,741 INFO mapreduce.JobSubmitter: number of splits:24
2018-05-15 19:14:30,789 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2018-05-15 19:14:31,866 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1526300938491_0016
2018-05-15 19:14:31,868 INFO mapreduce.JobSubmitter: Executing with tokens: []
2018-05-15 19:14:32,071 INFO conf.Configuration: resource-types.xml not found
2018-05-15 19:14:32,072 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2018-05-15 19:14:32,177 INFO impl.YarnClientImpl: Submitted application application_1526300938491_0016
2018-05-15 19:14:32,229 INFO mapreduce.Job: The url to track the job: http://node-master:18088/proxy/application_1526300938491_0016/
2018-05-15 19:14:32,231 INFO mapreduce.Job: Running job: job_1526300938491_0016
2018-05-15 19:14:38,323 INFO mapreduce.Job: Job job_1526300938491_0016 running in uber mode : false
2018-05-15 19:14:38,325 INFO mapreduce.Job: map 0% reduce 0%
2018-05-15 19:14:46,398 INFO mapreduce.Job: map 8% reduce 0%
2018-05-15 19:14:50,419 INFO mapreduce.Job: map 21% reduce 0%
2018-05-15 19:14:54,438 INFO mapreduce.Job: map 25% reduce 0%
2018-05-15 19:14:56,449 INFO mapreduce.Job: map 29% reduce 0%
2018-05-15 19:15:04,487 INFO mapreduce.Job: map 38% reduce 0%
2018-05-15 19:15:05,492 INFO mapreduce.Job: map 42% reduce 0%
2018-05-15 19:15:06,497 INFO mapreduce.Job: map 50% reduce 0%
2018-05-15 19:15:14,534 INFO mapreduce.Job: map 54% reduce 0%
2018-05-15 19:15:15,539 INFO mapreduce.Job: map 58% reduce 0%
2018-05-15 19:15:21,569 INFO mapreduce.Job: map 67% reduce 0%
2018-05-15 19:15:23,578 INFO mapreduce.Job: map 71% reduce 0%
2018-05-15 19:15:24,582 INFO mapreduce.Job: map 75% reduce 0%
2018-05-15 19:15:30,608 INFO mapreduce.Job: map 75% reduce 25%
2018-05-15 19:15:31,613 INFO mapreduce.Job: map 79% reduce 25%
2018-05-15 19:15:32,617 INFO mapreduce.Job: map 88% reduce 25%
2018-05-15 19:15:34,626 INFO mapreduce.Job: map 92% reduce 25%
2018-05-15 19:15:36,634 INFO mapreduce.Job: map 92% reduce 31%
2018-05-15 19:15:39,646 INFO mapreduce.Job: map 96% reduce 31%
2018-05-15 19:15:40,651 INFO mapreduce.Job: map 100% reduce 31%
2018-05-15 19:15:41,659 INFO mapreduce.Job: map 100% reduce 100%
2018-05-15 19:15:43,676 INFO mapreduce.Job: Job job_1526300938491_0016 completed successfully
2018-05-15 19:15:43,784 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=2208548
FILE: Number of bytes written=9857943
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=864242
HDFS: Number of bytes written=303
HDFS: Number of read operations=77
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=24
Launched reduce tasks=1
Data-local map tasks=24
Total time spent by all maps in occupied slots (ms)=167511
Total time spent by all reduces in occupied slots (ms)=32319
Total time spent by all map tasks (ms)=167511
Total time spent by all reduce tasks (ms)=32319
Total vcore-milliseconds taken by all map tasks=167511
Total vcore-milliseconds taken by all reduce tasks=32319
Total megabyte-milliseconds taken by all map tasks=343062528
Total megabyte-milliseconds taken by all reduce tasks=66189312
Map-Reduce Framework
Map input records=87876
Map output records=35060
Map output bytes=2138422
Map output materialized bytes=2208686
Input split bytes=3864
Combine input records=0
Combine output records=0
Reduce input groups=9
Reduce shuffle bytes=2208686
Reduce input records=35060
Reduce output records=9
Spilled Records=70120
Shuffled Maps =24
Failed Shuffles=0
Merged Map outputs=24
GC time elapsed (ms)=3650
CPU time spent (ms)=23560
Physical memory (bytes) snapshot=8264720384
Virtual memory (bytes) snapshot=66202730496
Total committed heap usage (bytes)=6004146176
Peak Map Physical memory (bytes)=346320896
Peak Map Virtual memory (bytes)=2619580416
Peak Reduce Physical memory (bytes)=210169856
Peak Reduce Virtual memory (bytes)=3486892032
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=860378
File Output Format Counters
Bytes Written=303流量数据导出到Mysql
使用Sqoop导出HDFS中的流量数据到Mysql中,需要创建有对应字段的新表,具体使用参见Sqoop导入导出文档。
hadoop streaming错误排查
使用hadoop streaming编写MR程序时最常见的错误:hadoop-streaming-subprocess-failed-with-code-1
对应的需要检查以下几个问题:
- 如果是通过./mapper.py的方式执行,则需要给mapper.py增加执行权限
- python shell命令执行时,py文件头部需要指定
#!/usr/bin/env python - Python环境和程序依赖的第三方库需要在集群中的所有节点上安装
上述几项没有问题之后,基本就是代码层面的问题了。需要逐层排查
参考:
- 用python + hadoop streaming 编写分布式程序(三) – 自定义功能
- 用python + hadoop streaming 编写分布式程序(一) – 原理介绍,样例程序与本地调试
- 官方-Hadoop Streaming
- 问题排查-Hadoop streaming - Subprocess failed with code 1
- Hadoop-Python实现Hadoop Streaming分组和二次排序
- IBM-Hadoop 压缩实现分析
- hadoop mapreduce开发实践之HDFS压缩文件(-cacheArchive)
- Hadoop Streaming入门
- 大数据采集、清洗、处理:使用MapReduce进行离线数据分析完整案例
- hadoop 代码中获取文件名