结合公司现状浅谈CMDB
本篇文章结合参考资料中的几篇CMDB的文章再加上目前公司的现状谈一谈CMDB。
CMDB概述
CMDB:configuration management database,配置管理数据库。CMDB本质上是一个数据库,提供数据的存储、查询、校验等操作,是一个集中式的数据托管中心,托管的内容包含所有的软硬件资产(configuration items)。各个部门各个团队各个系统下属的各种重要的软硬件资产都属于CMDB统一管理的内容。
公司运维现状
资产现状
全国各地区内网不互通。这个就是现状了,因为公司产品是为国家服务,所以全国各地的环境都在各自的内网中,安全性极高,在这种情况下,每个地区都配置了几个运维手工维护当地的环境,内外网完全隔离。
运维情况现状
由于公司资产地域分散且网络不互通,因此公司的自动化运维程度基本为0。整体上来说没有运维开发的岗位,目前的运维仍然停留在人工运维结合shell脚本的时代,这些其实都算不上自动化运维,前段时间,开始搞ansible自动化部署和升级的事情,整个过程都是shell脚本完成。为了控制人力成本,甚至否认一些用新技术。拿Python这门语言来说,本身很适合自动化运维,用于自动化升级那是再适合不过了,虽然底层会依赖shell,但是Python写出来的逻辑必然会更清楚,但是上层考虑到后续维护人员需要掌握Python和shell两种技术,最终还是否定了Python,其实也就是否定了自动化运维。转而几种人员去研究日志中心和nagios监控,自动化运维的事情也自然不了了之。
CMDB现状
目前公司里面还没有产生建设CMDB的萌芽,资产管理部门和运维中心团队有自己的配置库,也就是自建库。但是并没有将产品团队的软件资产列入配置管理的范围。各个产品团队使用Confluence文档服务器或者Excel表格(这种情况较多)管理自己的软硬件资源,并称之为资源台账。就服务器而言,经常不知道一个ip对应的服务器是否正在使用,由谁使用,这些信息一无所知。如果各个团队使用自建库,而不是通过文档形式来管理,那这种CMDB最多也只能算是各自为政的CMDB,并不是集中式的数据托管。
CMDB设计
最简单的设计:一种配置一个表
比如,ip单独成表,host单独成表
优点:配置简单直观
缺点:一旦某种配置需要修改字段,就需要修改代码,代码维护成本太高
复杂点的设计:列式数据存储
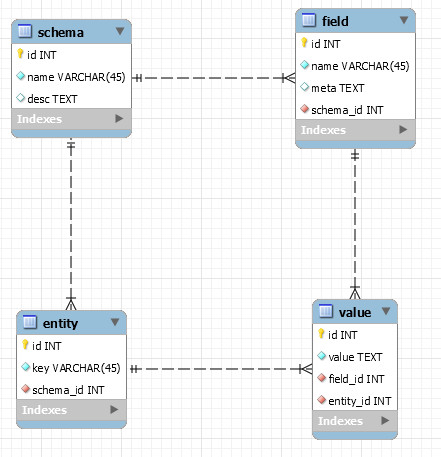
表名,列名,列值,行分开存放到四张张表(schema, filed, value, entity)
- schema:一个配置表在schema中就是一条记录,记录表的信息和描述。
- field:每一列的列名和列相关的meta信息都存放在field表中。
- entity:当作rowid使用,表示唯一衡量传统意义上的一行数据。
- value:存放每一条记录的每一列的值,即一个entity和一个field既可以确定一个值。
表的设计如下图:
整个设计的sql如下:
-- MySQL Workbench Forward Engineering
SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0;
SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0;
SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='TRADITIONAL,ALLOW_INVALID_DATES';
-- -----------------------------------------------------
-- Schema mydb
-- -----------------------------------------------------
-- -----------------------------------------------------
-- Schema mydb
-- -----------------------------------------------------
CREATE SCHEMA IF NOT EXISTS `mydb` DEFAULT CHARACTER SET utf8 ;
USE `mydb` ;
-- -----------------------------------------------------
-- Table `mydb`.`schema`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`schema` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(45) NOT NULL,
`desc` TEXT NULL,
PRIMARY KEY (`id`),
UNIQUE INDEX `name_UNIQUE` (`name` ASC))
ENGINE = InnoDB;
-- -----------------------------------------------------
-- Table `mydb`.`field`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`field` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(45) NOT NULL,
`meta` TEXT NULL,
`schema_id` INT NOT NULL,
PRIMARY KEY (`id`),
INDEX `fk_field_schema_idx` (`schema_id` ASC),
CONSTRAINT `fk_field_schema`
FOREIGN KEY (`schema_id`)
REFERENCES `mydb`.`schema` (`id`)
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
-- -----------------------------------------------------
-- Table `mydb`.`entity`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`entity` (
`id` INT NOT NULL AUTO_INCREMENT,
`key` VARCHAR(45) NOT NULL,
`schema_id` INT NOT NULL,
PRIMARY KEY (`id`),
INDEX `fk_entity_schema1_idx` (`schema_id` ASC),
CONSTRAINT `fk_entity_schema1`
FOREIGN KEY (`schema_id`)
REFERENCES `mydb`.`schema` (`id`)
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
-- -----------------------------------------------------
-- Table `mydb`.`value`
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `mydb`.`value` (
`id` INT NOT NULL AUTO_INCREMENT,
`value` TEXT NOT NULL,
`field_id` INT NOT NULL,
`entity_id` INT NOT NULL,
PRIMARY KEY (`id`),
INDEX `fk_value_field1_idx` (`field_id` ASC),
INDEX `fk_value_entity1_idx` (`entity_id` ASC),
INDEX `ux_value` (`field_id` ASC, `entity_id` ASC),
CONSTRAINT `fk_value_field1`
FOREIGN KEY (`field_id`)
REFERENCES `mydb`.`field` (`id`)
ON DELETE NO ACTION
ON UPDATE NO ACTION,
CONSTRAINT `fk_value_entity1`
FOREIGN KEY (`entity_id`)
REFERENCES `mydb`.`entity` (`id`)
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB;
SET SQL_MODE=@OLD_SQL_MODE;
SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS;
SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS;
数据库查询时需要提供(entity, schema, field, value)这样一个四元组才能得到结果。
优点:在线定义,表有变动时不需要修改代码,增加一列只需要向field表中插入一个字段。
缺点:复杂,增删改查时需要同时操作多个表,对数据的约束需要在应用层去实现,需要自己封装ORM,每一列的约束信息存放在field表的meta字段中。
更复杂的设计:数据多版本和回滚
增加数据多版本
CMDB存放的信息都是非常重要的信息,因此不允许修改数据,每一次修改数据都单独增加一条记录,这样就可以保证数据多版本。因此可以增加一个snapshot快照表,用来存放各个历史版本的数据。snapshot表的具体设计较复杂,暂不使用。
增加回滚
增加数据多版本之后对应的就可以增加一个回滚的功能,多版本基础上的回滚功能可以参考git的实现。
CMDB使用结论
强烈反对大型集中式CMDB。CMDB团队执行力不强,需求多变,短期内看不到价值等多种原因导致在大多数互联网公司CMDB是无法落地的,到目前为止除了华为也没几家公司能把CMDB落地直到发挥CMDB的价值(华为都花了7年的时间,更别说别的公司了)。
如果一定要使用CMDB,那只能使用分散式的各自为政的,各个团队使用各个团队的自建库,比如管IP库的就专门设计IP库,管账号库的就专门设计账号库,数据库之间通过各自提供的api通讯。但是分散式的缺点是从领导的角度看,看不到全局的数据,因此还需要做一个集中化的dashboard。
CMDB替代方案
CMDB在大多数互联网公司不可行,因此很多公司都另辟蹊径,比如一种方式常用的方式 Mesos
- Mesos:托管于Apache下C++开发的开源分布式资源管理系统
Mesos的调度框架可以有多种语言开发,包括Python。
参考