oracle的userenv和nls_lang详解
oracle的userenv和nls_lang详解
1、userenv最常见的使用
userenv函数返回当前会话(session)的相关信息。以下sql语句可以查询当前会话连接的数据库字符集
select userenv('language') from dual;有关userenv('parameter')返回值的官网介绍如下

意思就是:返回的是当前会话使用的language和territory。characterset是数据库的字符集。
下面我们就去验证这种情况
2、windows上plsql使用userenv
先看下数据库真实的语言、地区和字符集
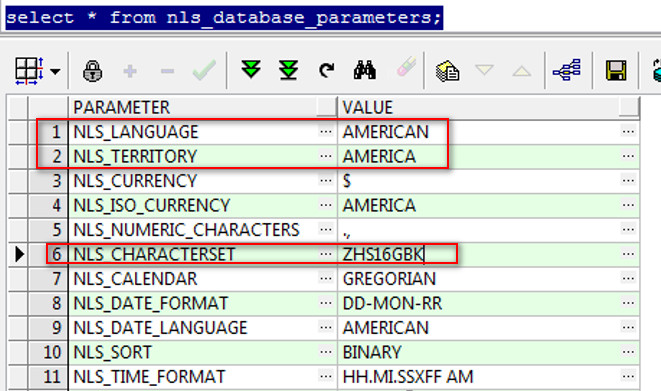
再看下windows上NLS_LANG环境变量

最后看下plsql上userenv执行的结果
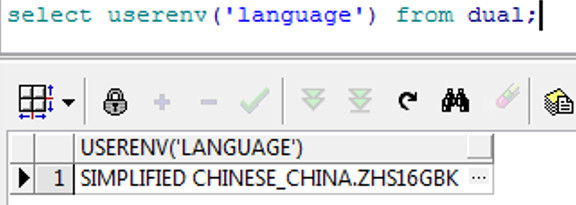
可以发现在windows上使用plsql的时候语言和地区使用的是plsql的环境变量NLS_LANG。
3、Linux上sqlplus使用userenv
首先看一下NLS_LANG为空的情况下userenv的返回值
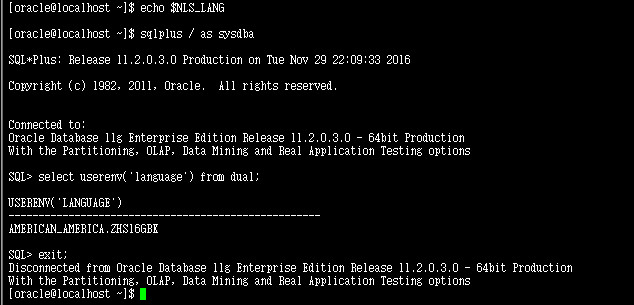
可以看到userenv('language')的返回值是AMERICAN_AMERICA.ZHS16GBK。这个值是怎么来的呢?从Oracle官网上看是取的默认值,如下图

- 如果Oracle通用安装程序没有指定NLS_LANG,则默认值是
AMERICAN_AMERICA.US7ASCII - 如果language没有指定,则language的默认值是
AMERICAN - 如果territory没有指定,则territory的默认值由language这个值派生而来。
- 如果charset没有指定,则在创建session的时候charset的值是数据库的characterset。
- NLS_LANG的每一个component都是可选的,如果只想指定NLS_LANG的territory,那么需要这样指定:
NLS_LANG=_JAPAN。此时territory的值是JAPAN
具体参见:Choosing a Locale with the NLS_LANG Environment Variable
下面继续验证
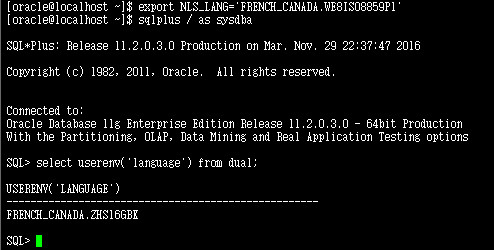
可以看到指定NLS_LANG之后,userenv('language')从会话中取得的语言和地区发生了变化,但是字符集仍然取得的是数据库的字符集。
4、问题:中文乱码在哪个环节产生的?
由以上分析可知,不管是什么样的客户端程序(不管是plsql还是sqlplus),在创建会话的时候字符都是取数据库本身的字符集。因此客户端程序和session的字符集不一致的时候会产生转码。如果转码的过程中出现了字节损失,则存储的真实数据就是损失之后的数据。至于我们看到的乱码是因为存储的数据会在查询的时候再次转码成客户端程序的字符集,由于数据缺失,因此就乱码了。
至于中文乱码的验证可以参见【字符集】论Oracle字符集“转码”过程
oracle的userenv和nls_lang详解
https://suncle.me/posts/2203031021/