Clickhouse创建分布式表以及表引擎介绍
表引擎
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
在读取时,引擎只需要输出所请求的列,但在某些情况下,引擎可以在响应请求时部分处理数据。
对于大多数正式的任务,应该使用MergeTree族中的引擎。
MergeTree 引擎系列的基本理念如下。当你有巨量数据要插入到表中,你要高效地一批批写入数据片段,并希望这些数据片段在后台按照一定规则合并。相比在插入时不断修改(重写)数据进存储,这种策略会高效很多。
各个引擎的具体使用参见官方文档:
- MergeTree:https://clickhouse.yandex/docs/zh/operations/table_engines/mergetree/
- ReplacingMergeTree:https://clickhouse.yandex/docs/zh/operations/table_engines/replacingmergetree/
- Replicated*MergeTree:https://clickhouse.yandex/docs/zh/operations/table_engines/replication/
- Distributed:https://clickhouse.yandex/docs/zh/operations/table_engines/distributed/
分布式怎么玩
使用ReplicatedMergeTree和Distributed引擎构建我们的分布式表,先看一个常用的表结构:
-- 每个机器都需要建立各自的replica table,也需要建Distributed table当做路由
create table dm.delphi_membership_properties_replica
(
membership_id int, -- comment '会员id',
membership_uid String, -- comment '会员uid',
business_group_id int, -- comment '商户id',
business_group_uid String , --comment '商户uid',
business_group_name String, -- comment '商户名',
business_id Nullable(int), -- comment '门店id',
business_uid Nullable(String), -- comment '门店uid',
business_name Nullable(String), -- comment '门店name',
membership_source String, -- comment '会员入会来源',
created_at DateTime,
calendar_date Date,
last_visited_date Date, -- comment '最近一次访问时间',
membership_level int, -- comment '会员等级',
customer_type String, -- comment '会员类型:新会员/忠诚会员/常来会员/淡忘会员/流失会员,根据最后一次访问时间和商户配置计算而来',
visit_count int, -- comment '到访次数',
consumptions_count Nullable(int), -- comment '消费次数',
consumptions_original_amount Nullable(Decimal128(2)), -- comment '消费总金额:原始金额',
consumptions_amount Nullable(Decimal128(2)), -- comment '消费总金额:实付金额',
average_consume Nullable(Decimal128(2)), -- comment '平均消费金额:原始金额/消费次数',
account_id int, -- comment '用户id',
account_uid String, -- comment '用户uid',
account_phone String, -- comment '用户手机',
age Nullable(int), -- comment '年龄',
birthday Nullable(String), -- comment '生日',
birthday_month Nullable(int), -- comment '生日月份',
birthday_day Nullable(int), -- comment '生日天',
birthday_year Nullable(int), -- comment '生日年',
zodiac String, -- comment '星座',
name Nullable(String), -- comment '姓名',
gender int, -- comment '性别',
profession Nullable(String), -- comment '职业',
country Nullable(String), -- comment '国家',
province Nullable(String), -- comment '省份',
city Nullable(String), -- comment '城市',
region Nullable(String), -- comment '商圈',
head_img_url Nullable(String), -- comment '头像',
wechat_name Nullable(String), -- comment '微信名',
wechat_city Nullable(String), -- comment '微信城市',
wechat_country Nullable(String), -- comment '微信国家',
wechat_province Nullable(String), -- comment '微信省份',
wechat_head_img_url Nullable(String), -- comment '微信头像',
wechat_groupid int, -- comment '微信组',
wechat_remark Nullable(String), -- comment '微信备注'
insert_time DateTime DEFAULT now(), -- 数据插入时间
insert_date Date DEFAULT toDate(now()) -- 数据插入日期
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/delphi_membership_properties_replica', '{replica}')
order by (business_group_uid, calendar_date, created_at, membership_uid);
create table dm.delphi_membership_properties as dm.delphi_membership_properties_replica
ENGINE = Distributed(ck_cluster, dm, delphi_membership_properties_replica, rand());delphi_membership_properties_replica是各个机器上的本地表,delphi_membership_properties是分布式表,比对下两个表的创建engine的区别。
ReplicatedMergeTree
在表引擎名称上加上 Replicated 前缀,就表示是一种复制表。ReplicatedMergeTree 参数:
zoo_path— ZooKeeper 中该表的路径。replica_name— ZooKeeper 中的该表所在的副本名称。
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/delphi_membership_properties_replica', '{replica}')
order by (business_group_uid, calendar_date, created_at, membership_uid);这些参数可以包含宏替换的占位符,即大括号的部分。它们会被替换为配置文件里 ‘macros’ 那部分配置的值
<yandex>
<macros>
<replica>172.31.59.118</replica>
<shard>01</shard>
<layer>01</layer>
</macros>
</yandex>“ZooKeeper 中该表的路径”对每个可复制表都要是唯一的。不同分片上的表要有不同的路径。 这种情况下,路径包含下面这些部分:
/clickhouse/tables/是公共前缀,官方推荐。{layer}-{shard}是分片标识部分table_name是该表在 ZooKeeper 中的名称。使其与 ClickHouse 中的表名相同比较好。 这里它被明确定义,跟 ClickHouse 表名不一样,它并不会被 RENAME 语句修改
注意点:
- 副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复制表和非复制表。
- DDL语句只会在单个服务器上执行,不会被复制
Distributed
Distributed(logs, default, hits[, sharding_key])分布式引擎参数:服务器配置文件中的集群名,远程数据库名,远程表名,数据分片键(可选)。数据分片键的概念就是数据插入时是根据什么原则分配到具体分片上的。
在上面的表结构中:
ENGINE = Distributed(ck_cluster, dm, delphi_membership_properties_replica, rand());表示将会从ck_cluster集群中dm.delphi_membership_properties_replica中读取数据。
集群的名称是在集群搭建时的metrika.xml文件中配置的,具体的可以看集群搭建部分的配置。可以在配置中配置任意数量的集群。
要查看集群,可使用“system.clusters”表。
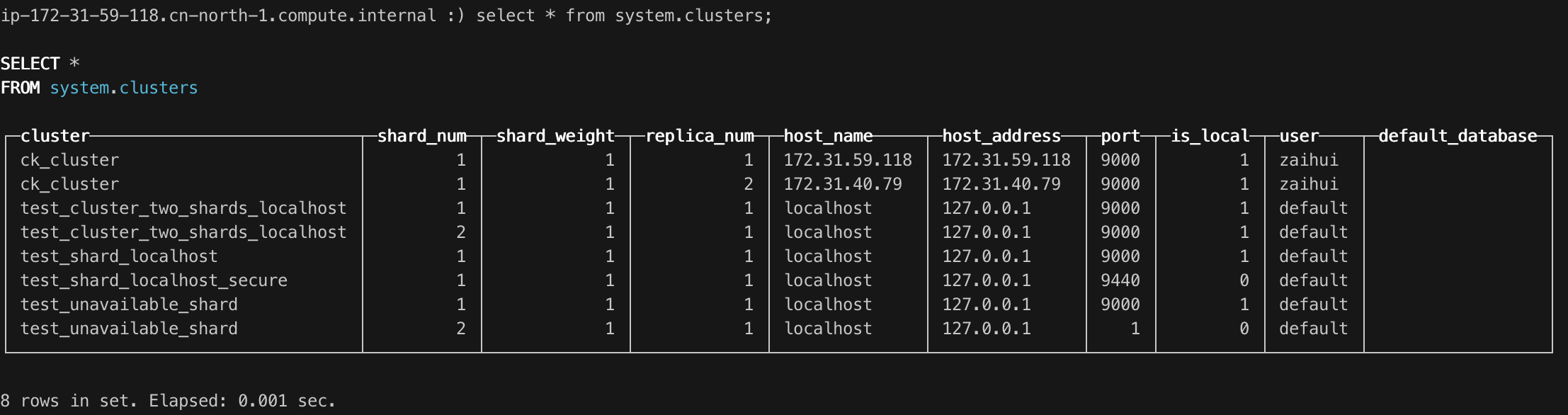
通过分布式引擎可以像使用本地服务器一样使用集群。但是,集群不是自动扩展的:必须编写集群配置到服务器配置文件中。
总结
clickhouse的分布式是一个彻底手动挡的分布式,无论是分布式集群的搭建还是还是表引擎的维护都能体现引擎的定制化感觉,相较于其他分布式比如hadoop等分布式来说,需要手动维护的内容较多。