阿里云大数据基础组件调研
阿里云大数据基础组件调研
EMR
阿里云 Elastic MapReduce(E-MapReduce)是运行在阿里云平台上的一种大数据处理的系统解决方案。
组件
阿里云EMR包含的组件(以EMR-3.20.0为例):
| 版本 | EMR-3.19.1 | EMR-3.20.0 |
|---|---|---|
| 发布时间 | 2019.4 | 2019.5 |
| Hadoop | 2.8.5 | 2.8.5 |
| Knox | 1.1.0 | 1.1.0 |
| ApacheDS | 2.0.0 | 2.0.0 |
| Spark | 2.4.1 | 2.4.2 |
| Hive | 3.1.1 | 3.1.1 |
| Tez | 0.9.1 | 0.9.1 |
| Pig | 0.14.0 | 0.14.0 |
| Sqoop | 1.4.7 | 1.4.7 |
| YARN | 2.8.5 | 2.8.5 |
| HDFS | 2.8.5 | 2.8.5 |
| Flink | 1.7.2 | 1.7.2 |
| Druid | 0.13.0 | 0.13.0 |
| HBase | 1.4.9 | 1.4.9 |
| Phoenix | 4.14.1 | 4.14.1 |
| Zookeeper | 3.4.13 | 3.4.13 |
| Livy | 0.60. | 0.60. |
| Presto | 0.213 | 0.213 |
| Storm | 1.2.2 | 1.2.2 |
| Impala | 2.12.2 | 2.12.2 |
| Flume | 1.8.0 | 1.8.0 |
| Hue | 4.1.0 | 4.1.0 |
| Oozie | 4.2.0 | 5.1.0 |
| Zeppelin | 0.8.0 | 0.8.1 |
| Ranger | 1.2.0 | 1.2.0 |
| Ganglia | 3.7.2 | 3.7.2 |
| OS | CentOS 7.4 | CentOS 7.4 |
| Tensorflow | 1.8.0 | |
| Kafka | 1.1.1 | 2.11 |
| Superset | 0.28.1 | 0.28.1 |
| Jupyter | 4.4.0 | |
| Analytics Zoo | 0.2.0 |
不清楚的组件说明:
- Oozie:Oozie是一个用于管理Apache Hadoop的任务的工作流调度系统,类似于airflow,都是用DAG
- Livy:Apache Livy是一个通过REST接口和Spark集群交互的服务
- Flink:Apache Flink可以替代MapReduce,并在很多方面对其进行改进。 除了其他功能之外,Flink还提供了更好的性能,并为Java和Scala提供了易用的API
- Zeppelin:Apache Zeppelin是一个让交互式数据分析变得可行的基于网页的notebook。Zeppelin提供了数据可视化的框架
- Ranger:Apache Ranger是一个集中式安全管理框架, 解决细颗粒度的授权和审计等问题
- Ganglia:Ganglia是一种可伸缩的分布式监控系统,广泛用于监控hadoop相关指标
- Impala:Apache Impala是一个开源的大规模并行处理(MPP) SQL查询引擎(数据存储在hadoop上)。但是单表查询速度慢于Presto,可以不用考虑
- Phoenix:Apache Phoenix是一个开源的、大规模并行关系数据库引擎(支持对HBase做OLTP处理)
- Knox:Apache Hadoop生态系统中的REST API和应用程序网关
- Pig:Pig是一个高级语言平台,用于分析和查询存储在HDFS中的大型数据集。 Pig中使用的语言称为PigLatin
- Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统
- Kerberos认证:E-MapReduce 从 2.7.x/3.5.x 版本开始支持创建安全类型的集群,即集群中的开源组件以 Kerberos 的安全模式启动,在这种安全环境下只有经过认证的客户端(Client)才能访问集群的服务(Service,如 HDFS)。
- Druid:Druid 是 Metamarkets 公司(一家为在线媒体或广告公司提供数据分析服务的公司)推出的一个分布式内存实时分析系统,用于解决如何在大规模数据集下进行快速的、交互式的查询和分析。
- Superset:Apache Superset是一个现代的、企业级商业智能web应用程序(by Airbnb)
- Analytics Zoo:在Spark和BigDL上快速构建深度学习应用的端到端的分析+AI平台
价格
目前使用的AWS的EMR的生产机器配置为
- 1 Master 和 4 Slave:1CPU-4Core-8vCore-32G-500G SSD
因为Master节点主要是存储元数据和一些主要组件的log以及做一些airflow等调度工作,不负责主要的计算任务,因此CPU可以比Slave节点低,但是内存应该比Slave高,因为元数据都是存在内存中。在之前的AWS EMR 32G环境中出现过OOM,同时阿里云也支持不同的节点使用不同的配置,还支持双Master配置。
- 在购买创建集群时一定记得勾选高可用选项,勾选后就会有双Master
最终,以2Master 和 4 Slave的配置进行价格计算:
| 节点 | 机器型号 | Cpu(vCore) | Mem(GB) | Disk(SSD GB) |
|---|---|---|---|---|
| Master1 | ecs.g5.2xlarge | 8 | 32 | 120+500 |
| Master2 | ecs.g5.2xlarge | 8 | 32 | 120+500 |
| Slave1 | ecs.g5.2xlarge | 8 | 32 | 120+100*4 |
| Slave2 | ecs.g5.2xlarge | 8 | 32 | 120+100*4 |
| Slave3 | ecs.g5.2xlarge | 8 | 32 | 120+100*4 |
| Slave4 | ecs.g5.2xlarge | 8 | 32 | 120+100*4 |
付费配置
包年包月是一次性支付一个长期的费用,价格相对来说会比较便宜,特别是包三年的时候折扣会很大。按量付费是根据实际使用的小时数来支付费用,每个小时计一次费用。适合与短期的测试或者是灵活的动态任务,价格相对来说会贵一些。
- 按量付费
- 包年包月
- 付费时长:您可选择购买 1 个月、2 个月、3 个月、6 个月、9 个月、1 年、2 年、3 年。包年包月如果购买一年则会在原价(12个月)的基础上打 85 折。
- 自动续费:到期前7天执行自动续费操作,续费时长为一个月。
包年包月
AWS EMR
AWS EMR是按年购买的,价格由两部分组成:EC2 + 产品费和流量费
目前AWS EMR生产5台机器测试3台机器,每台机器一年15000¥
AMS EMR每个月的产品费账单价格是3600¥,所以生产的5台机器占用2250¥
所以AWS EMR生产环境5台机器一年的价格是15000 * 5 + 2250 * 12 = 102000
Aliyun EMR
阿里云EMR 双Master的价格为:
1年:¥88944省: ¥35354.88 (单Master时的价格为73400)
2年:¥143904省: ¥104693.76
3年:¥158904省: ¥213992.64
按量付费
现价: ¥15.868/小时省: ¥2.124/小时
1年
365*24*15.868=139003.682年
139003.68 * 2 =278007.363年
139003.68 * 3 = 417011.04
结论
选择包年购买的价格比按量购买的价格低很多,相同配置下Aliyun和Aws的价格几乎相同,但是Aliyun支持双Master,因此选用Aliyun支持双Master保证HA
MaxCompute
大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的EB级数据仓库一站式解决方案。
和AWS的RedShift类似
有EMR的情况下意义不大
实时计算
阿里云实时计算是一套基于Apache Flink构建的一站式、高性能实时大数据处理平台,广泛适用于流式数据处理、离线数据处理、DataLake计算等场景。(本质是Flink加上一些运维管理和监控报警)
有EMR的情况下意义不大
OLAP
Online analytical processing
分析型数据库MySQL版
分析型数据库PostgreSQL版
HybridDB for MySQL (原PetaData)
云数据库HybridDB for MySQL (原名PetaData)是同时支持海量数据在线事务(OLTP)和在线分析(OLAP)的HTAP(Hybrid Transaction/Analytical Processing)关系型数据库。
理论上来说,啥都行的结果就是啥都不行
Data Lake Analytics
Data Lake Analytics是无服务器(Serverless)化的云上交互式查询分析服务。无需ETL,就可通过此服务在云上通过标准JDBC直接对阿里云OSS、TableStore的数据轻松进行查询和分析,以及无缝集成商业分析工具
结论
目前OLAP领域表现比较好的数据库都是列式的,阿里云提供的分析型数据都不是列式数据库,暂时不考虑使用阿里云的OLAP服务。
so,在单表查询性能上暂时没有找到可以替代clickhouse的阿里云OLAP数据库,在初期clickhouse维护比较麻烦的情况下,对于性能查询不敏感的还是使用综合性能更好的presto+hive
列式数据库更适合OLAP场景的原因?
下面部分的解释原因来自于Clickhouse官网:
列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍),下面详细解释了原因(通过图片更有利于直观理解):
行式
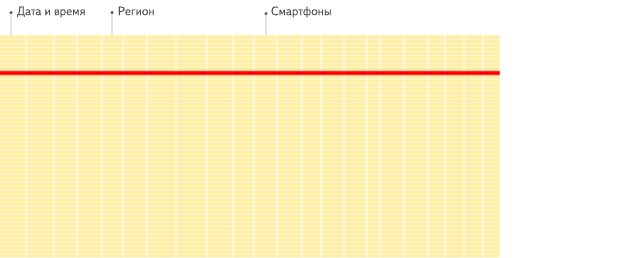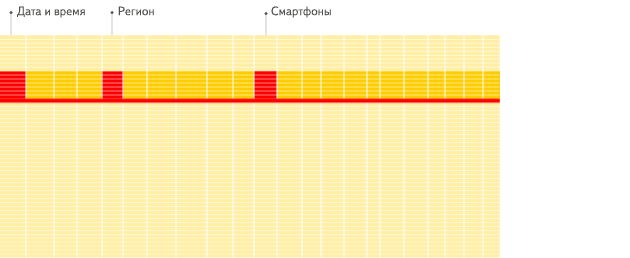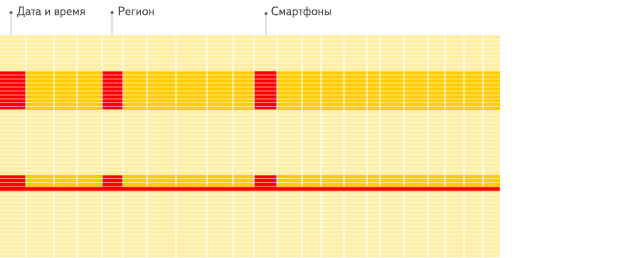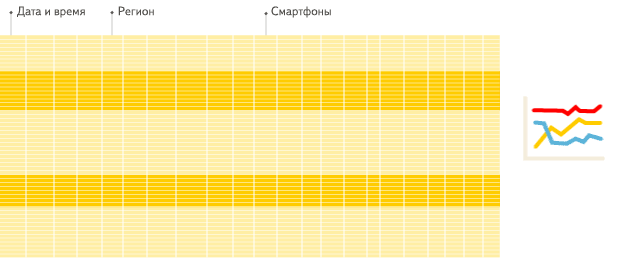
列式
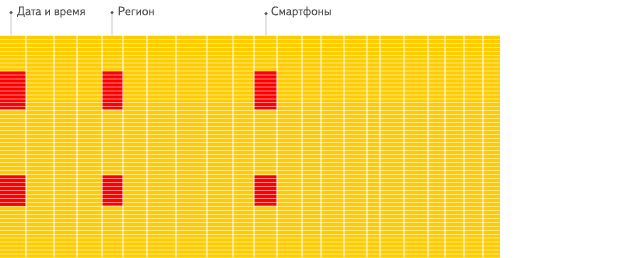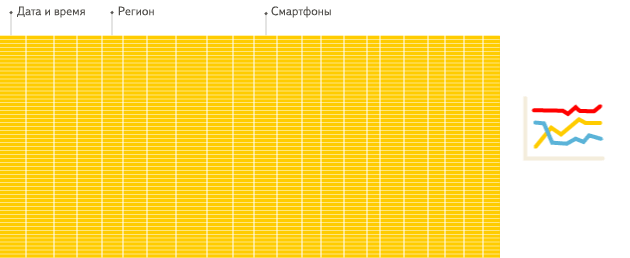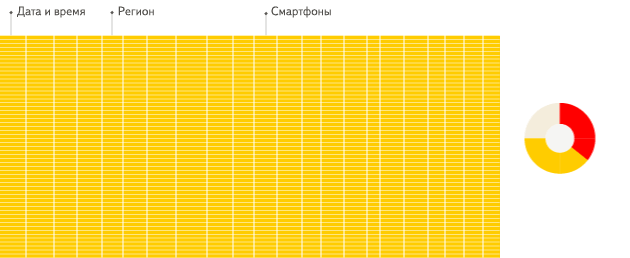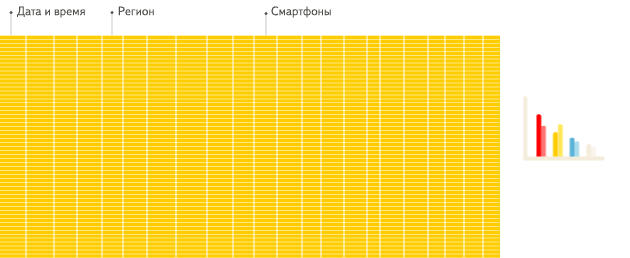
看到差别了么?下面将详细介绍为什么会发生这种情况。
Input/output
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
例如,查询“统计每个广告平台的记录数量”需要读取“广告平台ID”这一列,它在未压缩的情况下需要1个字节进行存储。如果大部分流量不是来自广告平台,那么这一列至少可以以十倍的压缩率被压缩。当采用快速压缩算法,它的解压速度最少在十亿字节(未压缩数据)每秒。换句话说,这个查询可以在单个服务器上以每秒大约几十亿行的速度进行处理。这实际上是当前实现的速度。
CPU
由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效。同时这将有助于实现一个几乎没有调用成本的查询引擎。如果你不这样做,使用任何一个机械硬盘,查询引擎都不可避免的停止CPU进行等待。所以,在数据按列存储并且按列执行是很有意义的。
有两种方法可以做到这一点:
- 向量引擎:所有的操作都是为向量而不是为单个值编写的。这意味着多个操作之间的不再需要频繁的调用,并且调用的成本基本可以忽略不计。操作代码包含一个优化的内部循环。
- 代码生成:生成一段代码,包含查询中的所有操作。
这是不应该在一个通用数据库中实现的,因为这在运行简单查询时是没有意义的。但是也有例外,例如,MemSQL使用代码生成来减少处理SQL查询的延迟(只是为了比较,分析型数据库通常需要优化的是吞吐而不是延迟)。
请注意,为了提高CPU效率,查询语言必须是声明型的(SQL或MDX), 或者至少一个向量(J,K)。 查询应该只包含隐式循环,允许进行优化。