数仓工作的简单介绍和对比
数仓工作的简单介绍和对比
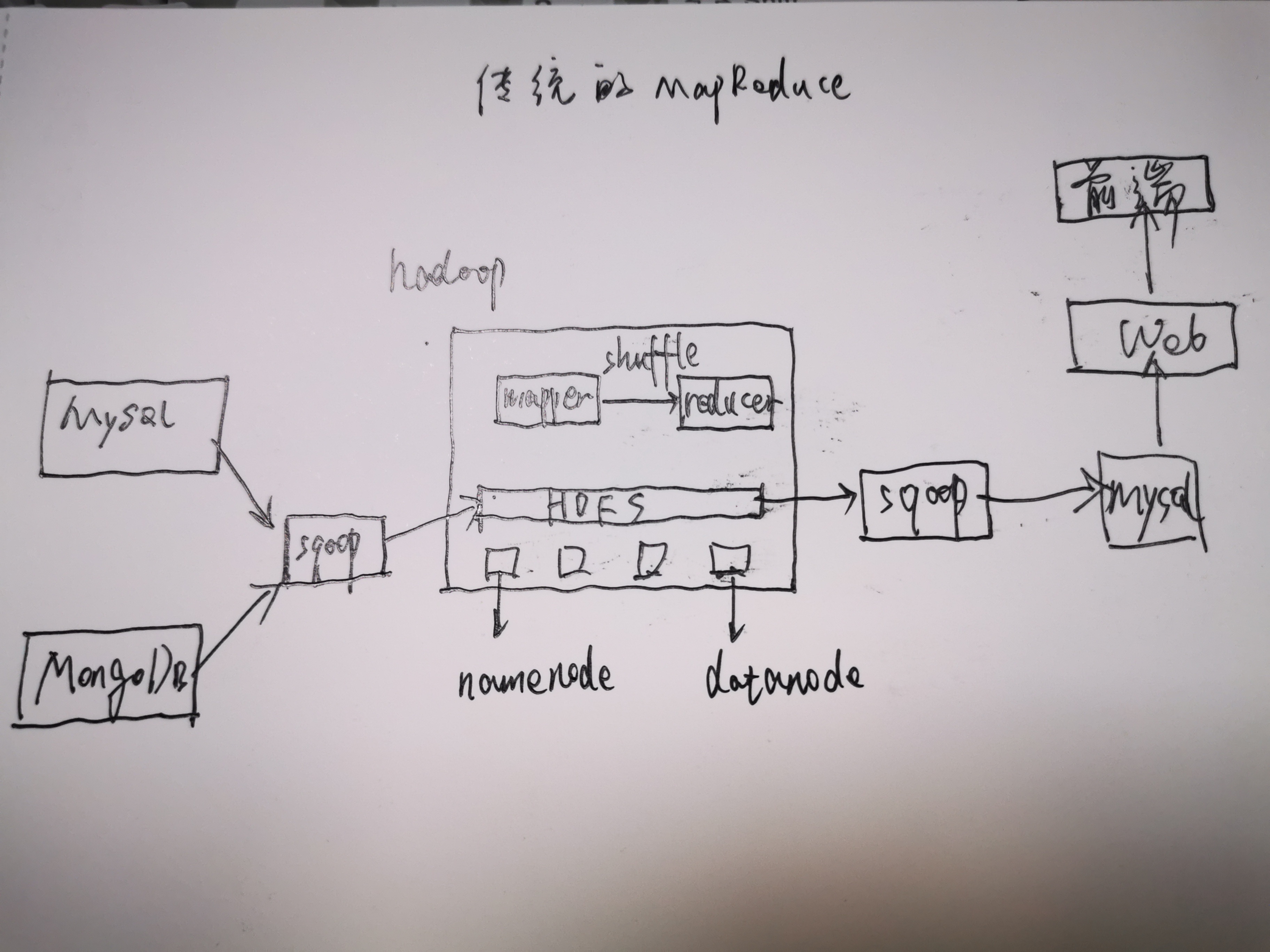
传统技术栈
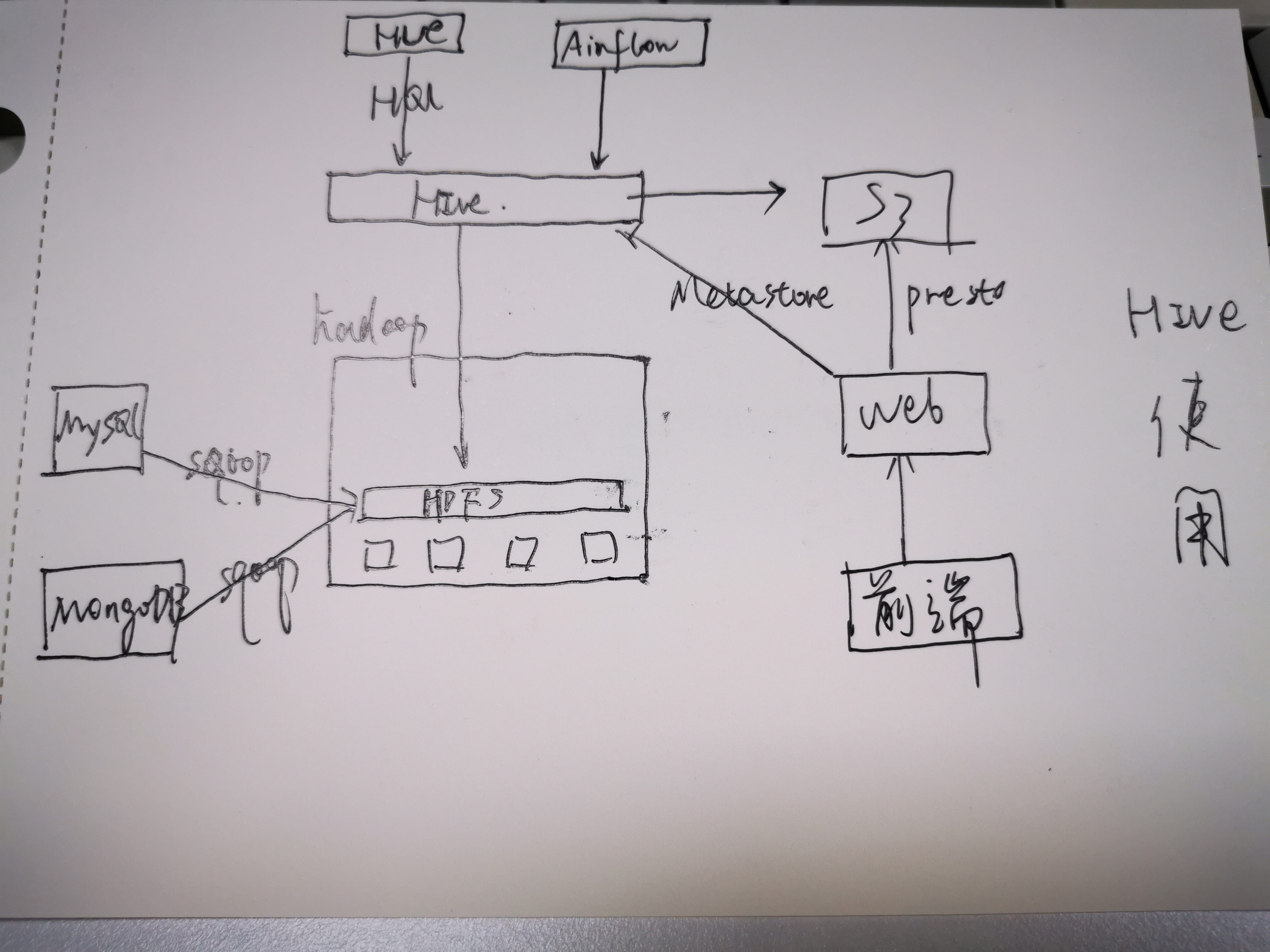
再惠技术栈
名词解释
| 技术 | 目的 |
|---|---|
| Hadoop | 生态环境,提供了一个可靠的共享存储和分析计算系统 |
| HDFS | Hadoop 分布式文件系统,解决文件分布式存储的问题 |
| MapReduce | 解决分布式的数据处理和分析 |
| Hive | 分析和管理存储在HDFS中的数据 |
| HBase | 解决数据的存储和检索 |
| Spark | 支持流式处理和批处理(spark streaming) |
| Storm | 流式计算 |
参考:https://suncle.me/2018/04/16/Hadoop-MapReduce-HDFS-Introduction/
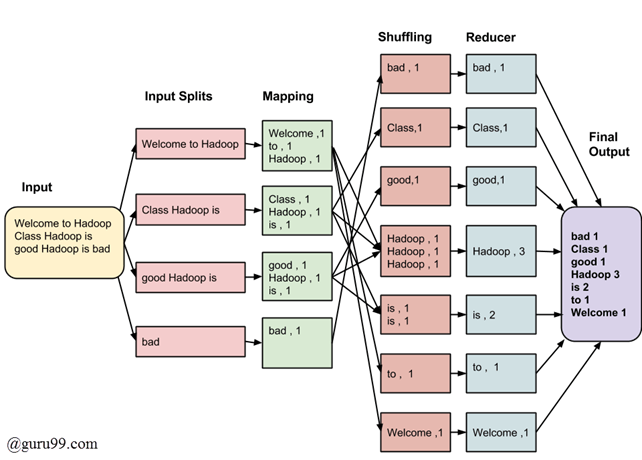
MapReduce工作原理
以Python为例
参考:https://suncle.me/2018/04/17/Writing-An-Hadoop-MapReduce-Program-In-Python/
hive工作原理
Hive最初是应Facebook每天产生的海量新兴社会网络数据进行管理和机器学习的需求而产生和发展的。
Hive是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析和管理(也就是说对存储在HDFS中的数据进行分析和管理,我们不想使用手工,我们建立一个工具把,那么这个工具就可以是hive)。
Hive定义了一种类似SQL的查询语言,被称为HQL
Hive可以允许用户编写自己定义的函数UDF,来在查询中使用。Hive中有3种UDF:
- User Defined Functions(UDF)
- User Defined Aggregation Functions(UDAF)
- User Defined Table Generating Functions(UDTF)。
Hive设计图:

- UI:用户界面,本质就是一个客户端,比如HUE(Hadoop User Experience)
- Driver:接收查询的组件。比如接收HUE和presto过来的查询
- Metastore:存储仓库中各种表和分区的所有结构信息
- Compiler:解析query,使用的是antlr解析sql为抽象语法树。从Metastore中获取表字段的类型或者其他元数据进行各种检查。然后生成执行计划。
- Execution engine:执行引擎。执行计划通常分为多步实现,也就是有阶段的概念,每个阶段都是一个mapreduce作业,然后就可以拿到hadoop中执行并且根据执行结果组装
技术栈升级
可以按照以下技术栈出现的顺序进行升级,目前阶段是打算把hive升级到spark,将spark streaming投入生产。后续向Beam靠拢。
QA
presto是如何从存储在s3上读取数据的?
从hive的metastore读取表的metadata,然后直接去读s3
DAG(Directed Acyclic Graph)?airflow调度?
DAG的本意是有向无环图,数仓里面经常说的DAG是指由一系列有顺序的阶段组成的执行计划。将DAG扔给airflow调度执行即可
参考:
- Apache Hive官方设计文档: https://cwiki.apache.org/confluence/display/Hive/Design
- ANTLR解析器:https://github.com/antlr/antlr4
- BNF范式:http://sighingnow.github.io/%E7%BC%96%E8%AF%91%E5%8E%9F%E7%90%86/bnf.html
- Hadoop、MapReduce、HDFS介绍:https://suncle.me/2018/04/16/Hadoop-MapReduce-HDFS-Introduction
数仓工作的简单介绍和对比
https://suncle.me/posts/2688010521/